Introduction to ICL (In Context Learning, like CoT, ToT,GoT...)
介绍ICL(In Context Learning),包括CoT, ToT, GoT, XoT, DoT等。
Intro
ICL (By 2024):
- [2022.01] CoT (Chain of Thought)
- [2022.03] CoT-SC (CoT with Self-Consistency)
- [2023.05] ToT (Tree of Thought)
- [2023.08] GoT (Graph of Thought)
- [2023.11] XoT (Everything of Thought)
- [2024.09] DoT (Dynamic of Thought)
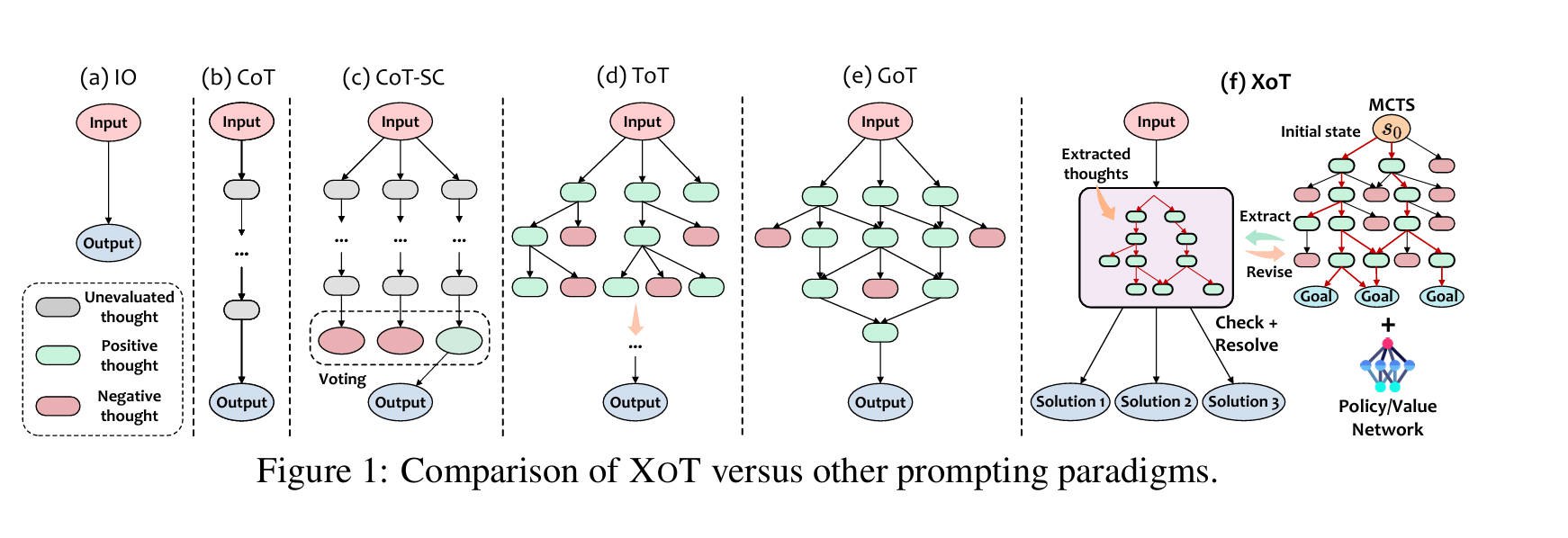
CoT
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Q1: 要解决的问题是什么?
Naive Chat方式无法解决复杂推理任务
Q2: 要验证的假设是什么?
通过在ICL中加入中间推理步骤,可以显著提高大型语言模型在复杂推理任务中的表现。
Q3: 验证方法是什么?
论文的关键解决方案是”chain-of-thought prompting”,通过在提示中引入中间推理步骤,帮助模型逐步解决问题,提高准确性和可解释性。
Q4: 结论是什么?
实验结果全面且一致地支持了论文的科学假设,表明链式思维提示能够显著提升大型语言模型在复杂推理任务中的表现
CoT-SC
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Q1: 要解决的问题是什么?
直觉认知:复杂推理任务通常有多种解法,使用CoT的贪婪解码方式,会导致模型只能稳定找到一个极点,可能会导致错误答案。
Q2: 要验证的假设是什么?
如果多种思维方式导致相同的答案,答案正确的可能性越大。
也就是说,对推理路径进行多样性采样,可以提高模型在复杂推理任务中的表现。
Q3: 验证方法是什么?
在生成推理链的过程中,使用采样代替贪婪解码,以生成多个不同的推理路径。这些路径可能由于随机性和多样性在推理步骤上有所不同。
- 温度采样(Temperature Sampling)
- Top-k 采样
- 核采样(Nucleus Sampling)
Q4: 结论是什么?
基于多个不同规模的LLM,在数学和常识上限制提升了准确率。
但成本会显著增加,实际中最好使用少量路径(5~10)。
ToT
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Q1: 要解决的问题是什么?
克服现有语言模型在应对需要战略规划、探索或前瞻性决策的问题时的局限性.
传统语言模型(如GPT-4)依赖于左到右的逐步决策,这种机制在处理需要全局性思考和多路径探索的任务时往往表现不佳。
Q2: 要验证的假设是什么?
人们有两种参与决策的模式:
- 一种是快速的,自动的、无意识的模式(“系统1”)
- 另一种是缓慢的、深思熟虑的、有意识的模式(“系统2”)
假设简单的Naive Chat 或 CoT,类比于系统1;经过深思熟虑的ToT规划过程,维护并探索当前的多种替代方案,相当于系统2.
Q3: 验证方法是什么?
ToT框架能够对问题的解决过程进行细化,将其看作是一棵“思维树”,每一个“节点”代表一个部分解决方案,而每条“分支”则对应对该部分方案的不同扩展或操作。通过这种方式,ToT可以在决策过程中自我评估,并灵活选择向前、回溯或进行多路径探索。
- 问题分解: 复杂问题 -> 多个可以逐步解决的子问题
- 思维生成:Naive Chat 或 CoT
- 状态评估:丢弃 或 探索
- 搜索算法的选择:BFS 或 DFS
- 自我评估与路径选择:回溯 或 前进
Q4: 结论是什么?
在需要系统规划和推理的任务中,ToT的成功率显著提高。但成本上升较大。
GoT
Graph of Thoughts: Solving Elaborate Problems with Large Language Models
Q1: 要解决的问题是什么?
CoT、CoT-SC、ToT 仍然具有很多局限性,无法模拟更复杂的思维网络。
例如,当处理一个新想法时,人类不仅会遵循思维链(如CoT中那样)或尝试不同的独立思维(如ToT中那样),实际上会形成一个更复杂的思维网络,类似于图的模式。
Q2: 要验证的假设是什么?
人类的任务解决过程通常是非线性的,涉及到将中间解决方案组合成最终解决方案,或者在发现新见解时改变推理的路径。GoT使用图结构可以解决更复杂的推理问题。
Q3: 验证方法是什么?
设计一个模块化的架构,包括多个相互协作的组件,来实现GoT。
为了更通俗地理解 GoT 的流程,我们可以用将小说改编为漫画的例子来演示整个过程。
推理过程建模:假设我们的任务是将一本小说改编为一系列漫画章节。我们将每一章节(甚至更小的部分,如段落或场景)建模为一个思维节点。每个节点代表一种叙事片段,而这些节点之间的关系形成了小说的整体故事结构。这些关系可能包括时间顺序、因果关系或角色之间的互动。
- 思维转换:
- 聚合转换:我们可以将小说中多个互相关联的片段聚合为一个新的漫画情节。
- 细化转换:对某个章节的叙事进行细化,使其更加适合漫画的表现方式。
- 生成转换:根据已有的故事部分生成新内容。例如,从一个主要情节生成多个支线情节
- 评分与排序:我们会对每个转换后的思维进行评分,评估其对于漫画表现力的提升。例如,一个场景是否能够有效传达角色的情感?
- 模块化架构:
- 提示器:会生成如何改编章节的具体指令,比如“将这个段落改为一个有张力的场景”。
- 解析器:从生成的内容中提取出有效的信息,例如哪些部分需要继续细化或者调整。
- 评分模块:验证漫画情节是否符合原著的精神,并给出相应的评分。
- 控制器:负责整体进度的管理,决定何时进行哪些转换,什么时候结束这个改编过程。
- 操作图与推理状态图:
- 操作图(GoO)用于描述小说改编的各个步骤,例如先分章节,再分场景,然后再合并某些场景。
- 推理状态图(GRS)动态跟踪改编的进展,记录哪些章节已经改编,哪些还需要进一步处理。
Q4: 结论是什么?
GoT 表现更为出色, 成本较ToT更低。
XoT
Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation
Q1: 要解决的问题是什么?
不可能三角:性能、效率和灵活性。无法使三个维度同时达到性能优化。
现有的思维最多只能展现这三个属性中的两个。
Q2: 要验证的假设是什么?
XOT利用预训练的强化学习(RL)和蒙特卡洛树搜索(MCTS),结合轻量级策略和价值网络,对特定任务进行思维搜索的预训练,然后推广到新问题。
能够同时实现灵活性、性能和效率。
Q3: 验证方法是什么?【未理解,暂时粘贴复制】
PASS
Q4: 结论是什么?
在特定任务上能实现性能、效率和灵活性的同时优化。
具有以下局限性:
- 需要特定任务的预训练
- 局限在特定任务的推理,无法泛化
- 可解释性较差
- 对任务有要求,最好是有精确答案的任务
DoT
Q1: 要解决的问题是什么?
CoT是线性推理,局限性较大。ToT、GoT、XoT需要非常复杂的多推理路径管理,计算量大且复杂。
推理过程中保持逻辑的一致性和正确性是一个挑战,尤其是在没有外部监督的情况下。
Q2: 要验证的假设是什么?
DoT通过在单个LLM内构建有向无环图(DAG)来模拟逻辑推理,允许模型探索复杂的推理路径,同时保持逻辑一致性。
Q3: 验证方法是什么?【未理解,暂时粘贴复制】
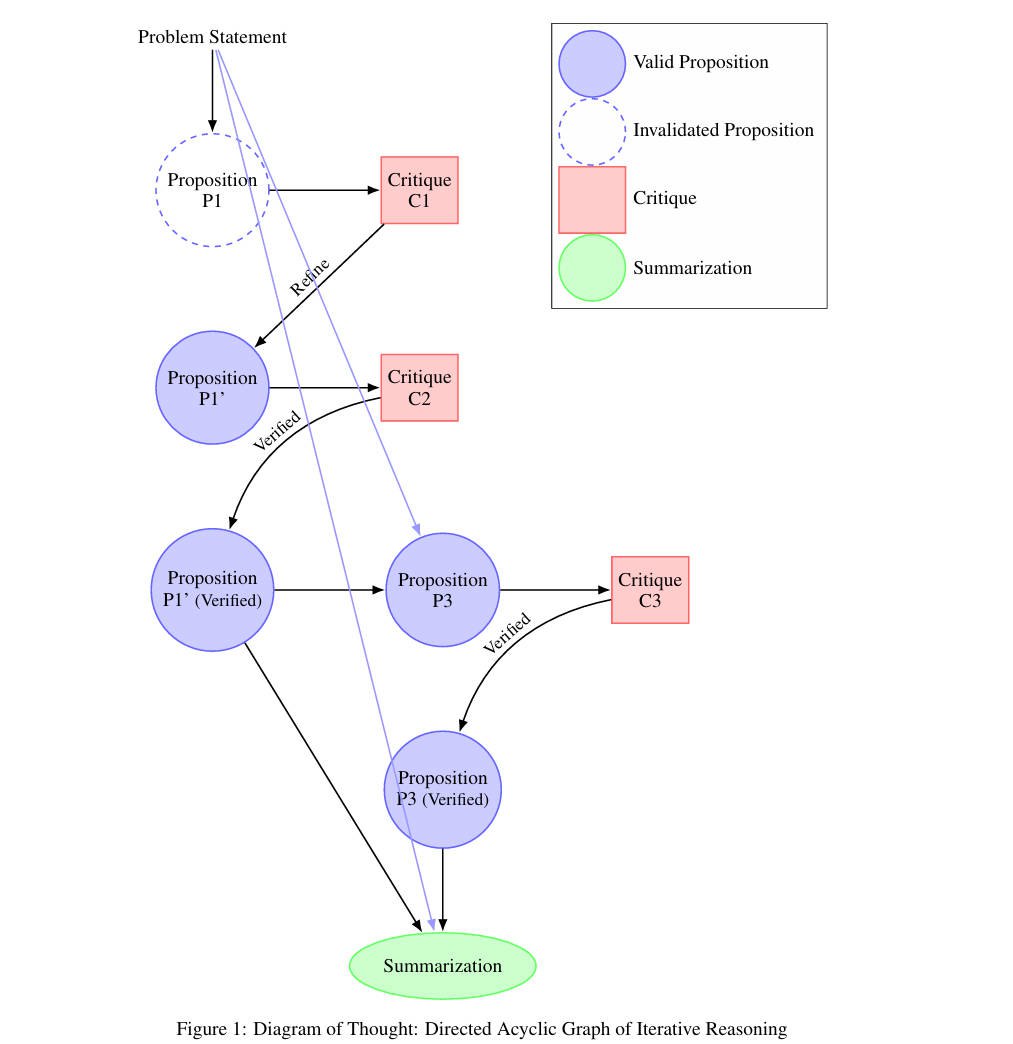
DoT框架在单个LLM内部通过管理三个关键角色来完成思维链的构建:
- 提议者(Proposers):负责提出新的论点或逻辑步骤,并将这些新内容作为节点加入到有向无环图(DAG)中。
- 批评者(Critics):负责对提出的论点进行评估,识别其中的错误、不一致性或逻辑上的缺陷,并在DAG中添加相应的批评节点。
- 总结者(Summarizers):负责将经过验证的论点整合成一个连贯的推理链条,这本质上是对DAG进行拓扑排序,以生成最终的推理结果。
DoT的推理过程如下:
(其实就是迭代请求LLM,过程中使用了多Agent写作;但论文说有很好的拓扑理论支持(不明觉厉)。并且这是姚院士挂名的文章。。。)
- 提案者引入一个命题,将其作为DAG中的一个新节点。
- 批评者评估该命题,要么验证它,要么提供批评。如果提供了批评,就会在DAG中添加一个新的节点,并在命题和批评之间建立边。
- 基于批评,提案者生成一个改进的命题,这在DAG中表示为一个新的节点。
- 这个过程重复进行,直到命题被验证。
- 一旦建立了足够的有效命题,总结者就会综合推理,对DAG进行拓扑排序,以产生一个连贯的思维链。
Q4: 结论是什么?
- DAG超越了CoT或ToT, 能够捕获复杂的逻辑推理
- 在拓扑理论中形式化DoT, 提供了数学基础
- 在特定任务上能实现性能、效率和灵活性的同时优化。
- 具有以下局限性:
- 需要特定任务的预训练
- 局限在特定任务的推理,无法泛化 (但LLM作为批评者也会产生幻觉的,所以真的有那么好吗?)