ChatGen - Automatic Text-to-Image Generation From FreeStyle Chatting
ChatGen(Auto Text2Image)论文阅读
Intro
Intro
论文:ChatGen: Automatic Text-to-Image Generation From FreeStyle Chatting
ChatGen,是一个文生图应用解决方案,希望能够自动化用户的试错步骤。
流程:用户自然语言输入 –> LLM craft prompts –> Recall select models —> Load configure arguments —> SD Generate
主要贡献:
- 提出新问题:如何自动化T2I
- 提出了多阶段进化框架:ChatGenEvo, 逐步完善推理信息
- 引入了为自动T2I设计的新型评测基准:ChatGenBench
结论:提出了新颖的问题,有很大发展空间。
自评(纯属扯淡,认真你就输了):
- 没有明确的横向对比数据
- Idea适应性欠妥,明显是解决SD1.5时代的小痛点,在SD3、Flux时代,是否还有价值?存疑
- [待补充] 看看ChatGenEvo 和 ChatGenBench 是否有参考价值

Question List
- Q1: 本文要解决的问题是什么?是不是一个有价值的问题?
- Q2:本文提到了哪些先前工作?
- Q3:ChatGenEvo的框架流程是怎么实现的?亮点在哪里?
- Q4:ChatGenBench是怎么构建的?是否严谨?
- Q5:下一步需要解决的问题?或努力的方向?
Answer
Q1:本文要解决的问题是什么?是不是一个有价值的问题?
问题: 开源社区中T2I模型的快速发展也为用户带来了显著的挑战。
当非专家尝试创建具有特定要求的图像时,他们经常遇到一个涉及多个繁琐步骤的试错过程,包括:制定合适的提示、选择适当的模型和配置特定模型参数。
每个步骤的复杂性和不确定性将这个过程变成了一个艰难的旅程,类似于“迷宫中的老鼠”。
在现实世界场景中,这个迭代过程消耗了大量的时间和资源,因为用户不断调整设置以重新生成图像。
因此,我们提出了一个挑战性的问题:我们能否自动化T2I生成中的这些劳动密集型步骤,允许用户以聊天风格简单地描述他们的需求,并轻松地获得所需的图像?
问题有价值吗: 没有应用场景,无法落地。
- 这个问题是SD1.5时代才有的,风格模型繁多,参数各异。
但是,模型能力是否优劣的,是需要精挑细选的,合适的可能就没有几个,用不着去Select。
用户的痛点在于模型不稳定导致抽卡(咒语占的比重很小,被过分关注了)。 - 在SD3和Flux时代,模型数量急剧减少,可能就几个了,模型支持自然语言格式的Prompt,无需咒语。这下连Craft prompts 可能都不需要了。
Q2:本文提到了哪些先前工作?
BeautifulPrompt
BeautifulPrompt: Towards Automatic Prompt Engineering for Text-to-Image Synthesis Author:阿里云团队、华南理工大学 Date:2023.11
Goal:使用LLM自动优化提示语(T2I)
Method: 类似LLM的训练三段式, SFT, RM_model, PPO
1. 数据收集
- 数据源:DiffusionDB
- 低质/高质区分方法:长度和标签
- 构建方法
a. BLIP对(有高质Prompt的)图像进行Caption,作为低质Prompt
b. 使用ChatGPT对高质Prompt进行总结,作为低质Prompt
c. 使用ChatGPT对低质Prompt进行优化,作为高质Prompt
- 筛选:色情、政治敏感、美观度
2. SFT
- 基于BLOOM
- input: 低质Prompt
- output:高质Prompt
3. RM
- PickScore: 基于Clip训练,对预测人类对图像的偏好方面表现出超人的表现
- Aesthetic Score: 基于clip-ViT 用于评估图片的美学质量
- Alpha因子:加权组合两个评分作为最终奖励
4. PPO
略,不熟,占坑!
DiffAgent
DiffAgent: Fast and Accurate Text-to-Image API Selection with Large Language Model Author:中科院、教育部、厦门大学、上海AI labs、上海较大 Date:2024.04
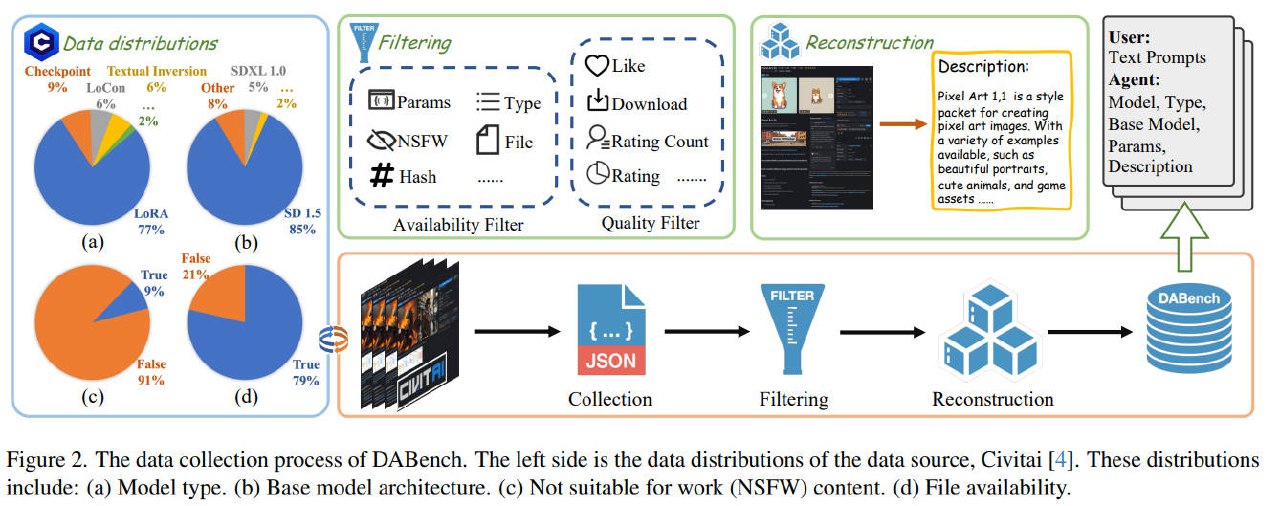

Goal:利用LLM的能力辅助从Civitai的众多模型中,选择合适的模型
Method: SFT, RM, RRHF(人类反馈排名)
1. 数据收集 - DABench
- 数据源:Civitai (相当于把C站的模型、图片全部扒下来并分析)
- 数据格式:(T2I API, 用户提示)
2. SFT
- 基于Llama 2
- input: Text Prompt
- output:Model, Type, Base Model, Params, Description
3. RM
- Clip Score: 使用CLIP模型的文本和图像特征的余弦相似度来计算得分
- ImageReward: 基于Blip, 通过交叉注意力机制结合文本和图像特征,并使用一个多层感知机(MLP)来生成一个标量得分
- Human Preference Score v2 (HPS v2):这是一个通过CLIP-H模型微调得到的评分模型,能够更准确地预测文本生成图像的人类偏好
4. RRHF
a. 采样:使用DiffAgent-SFT,对给定的文本提示,采样多个结果
b. 验证:验证API的有效性
c. 生图:调用对应T2I,生成图像
d. RM打分:使用RM模型进行打分
e. 计算条件概率:使用SFT模型,计算每个响应的条件概率
f. RRHF优化模型:计算排名损失(Lrank)和交叉熵损失(Lce)
g. 梯度优化:结合Lrank和Lce形成最终Loss, 用于优化SFT模型
Q3:ChatGenEvo的框架流程是怎么实现的?亮点在哪里?
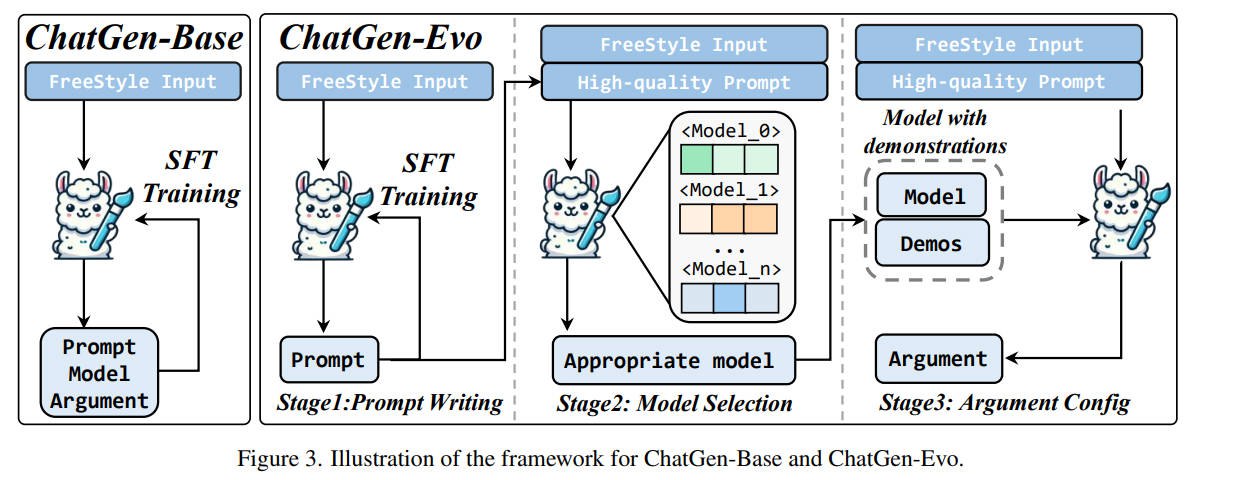
1. SFT
Goal: 学习如何将自由风格的输入转换成高质量的提示
Model: InternVL2
2. Model Selection via ModelToken
Goal: 在模型的词汇表中引入ModelToken,扩展模型的能力,使其能够选择最合适的图像生成模型。
Strategy: 在训练阶段,用户输入c和提示p被连接作为一个前缀,紧接着添加特殊的模型 token <Model i> 作为下一个 token 预测的真值。 训练目标是优化 ModelToken 的嵌入矩阵,而不是整个 MLLM 的参数。
Question: 为什么用预测下一个token的方式?为什么不同检索召回?
3. Argument Configuration via ICL
Goal: 通过ICL,输入prompt、model、示例,输出参数
亮点:
- 第一反应用了相似度召回,没想到用的是Next-token generate,有点意外
Q4:ChatGenBench是怎么构建的?是否严谨?
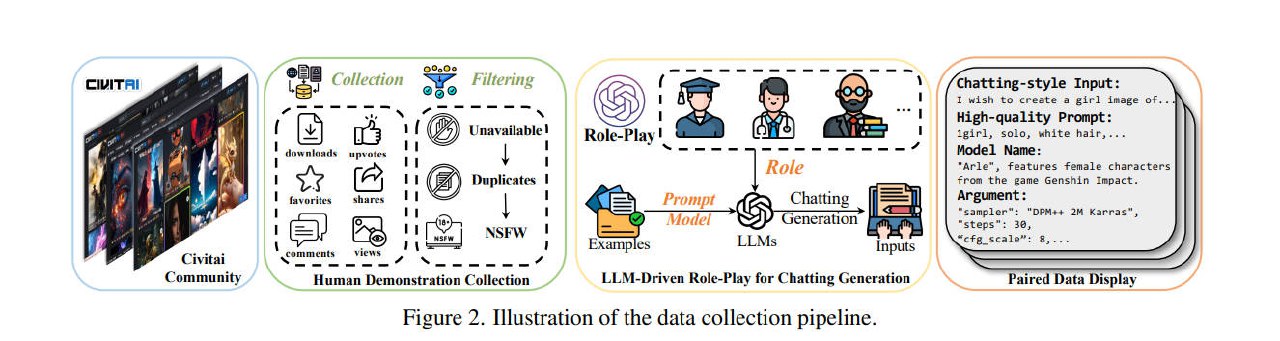
- 数据源:Civitai (相当于把C站的模型、图片全部扒下来并分析)
- 高质量Prompt:prompt、模型、参数,收集过滤自C站
- FreeStyle输入:使用LLM进行角色扮演,将Prompt转换成带有角色语气和习惯的自由风格聊天输入
Q5:下一步需要解决的问题?或努力的方向?
自动化Text2Image是一个很有价值的方向,但不能着眼于当前形势,要放眼未来两年。
未来趋势:
- 模型语言能力不断增强,Prompt不再需要精雕细琢,例如:Flux和SD3.5
- 未来模型会逐渐收缩,最终集中在少数几个,例如:Midjournal、Flux、SD、Redpanda等,不需要再筛选
努力方向:
- Agent的确是趋势,如何能生成连贯的多图,应用场景非常多:漫画、视频、多图推文、营销素材
- 其中最关键的是Judge,如何评判多图是否连贯?是否风格一致?是否符合要求?