DiffSensei - Bridging Multi-Modal LLMs and Diffusion Models for Customized Manga Generation
精读DiffSensei
Intro
Intro
论文:DiffSensei: Bridging Multi-Modal LLMs and Diffusion Models for Customized Manga Generation
DiffSensei: 一个创新框架,转么用于生成动态多角色控制的漫画。通过桥接MLLM和Diffusion Model, 实现可控的漫画生成。
主要贡献:
- DiffSensei在漫画生成领域上,超越了现有模型
- MangaZero数据集:43K漫画页面和427K个注释面板,支持在连续帧中可视化多变的角色互动和动作。
结论:DiffSensei实现了卓越的、角色一致的面板,这些面板能够动态地响应文本提示,超越了现有方法,推进了故事可视化领域的发展。
Question List
- Q1: 论文想要解决的主要问题是什么?
- Q2:这是一个有价值的问题?
- Q3:先前的解决方案有哪些?存在哪些难点?
- Q4:论文提出的假设是什么?
- Q5:MangaZero数据集是如何构建的?如何筛选数据?如何评估数据是否完备?
- Q6:DiffSensei具体是如何实现的?
- Q7:效果如何?结论是什么?
- Q8:下一步优化的方向是什么?
Q1:论文想要解决的主要问题是什么?
任务定义:故事可视化(Story visualization),即从文本描述中创建视觉叙事的任务。
主要问题:通常缺乏对角色外观和互动的有效控制,特别是多角色场景中。
特别是在漫画领域,需要跨面板保持一致的角色、精确的布局控制以定位多个角色,以及将对话无缝集成到连贯、视觉上吸引人的方式中。
漫画生成领域的难题:
- 通常不能跨场景定制角色,有一些办法能解决,但仍不自然,比较僵硬;限制了角色表达和叙事。
- 没有提供对布局和对话放置的必要控制
Q2:这是一个有价值的问题?
有价值!
随着信息爆炸、时间碎片化、多模态技术发展;信息的组织方式一定会变得越来越直观,从文字 –> 音频 –> 视觉 –> 脑机。这是个逐渐演化的过程,也可能会跳跃发展。但在当前这个时间点,视觉叙事正在逐渐崛起。
Q3:先前的解决方案有哪些?存在哪些难点?
漫画领域主要有两大难点:角色一致性,角色动作可控性
对于角色一致性:
- 文本(+图像): 不稳定
- LoRA: 源于缺乏捕获同一角色在不同表情和姿势中的多种外观的数据集
- Traing-Free: 类似IP-Adapter,常常导致角色僵硬, 限制了动态叙事所需的表情和动作的多样性
Q4:论文提出的假设是什么?
假设,之前的难点,主要原因在于:
- 缺少捕获同一角色在不同表情和姿势中的多种外观的数据集。
- 当前技术对文本的提示相应不够好。
Ok, 解决这两个问题:
- 收集一个大规模Manga数据集
- 使用MLLM提升文本响应能力
- 采用了掩码注意力机制来管理角色布局
- 专门针对漫画的对话嵌入技术,允许对对话放置进行精确控制
Q5:MangaZero数据集是如何构建的?如何筛选数据?如何评估数据是否完备?
任务定义
首先定义任务及模式,然后针对性构建数据集。
任务定义:定制漫画生成
为了在N个面板(或帧)中生成一个漫画故事,输入包括:
- 每个面板的文本提示T0, T1, …, TN−1,
- 角色图像I = I0, I1, …, IK−1,
- 每个面板的角色边界框Bc 0, Bc 1, …, Bc N−1,
- 每个面板的对话边界框Bd 0, Bd 1, …, Bd N−1。
一个面板的可视化表示为Pi = Φθ(Ti, I, Bc i, Bd i),其中Φ是整体模型函数,θ代表模型学习的参数。
数据集构建
参照了著名数据集Manga109, 但包含了更多2000年后的漫画。

- 下载: 从MangaDex下载
选择了48个漫画系列,每个系列下载1000页, 共获得43K个双页图像。 - 标注:最新的漫画理解模型Magi
对于漫画特定的注释,包括面板边界框、角色边界框、角色ID和对话边界框。由人工参与校验角色ID。 - 生成标题:为每个Panel生成标题
使用LLaVA-v1.6-34B
Q6:DiffSensei具体是如何实现的?
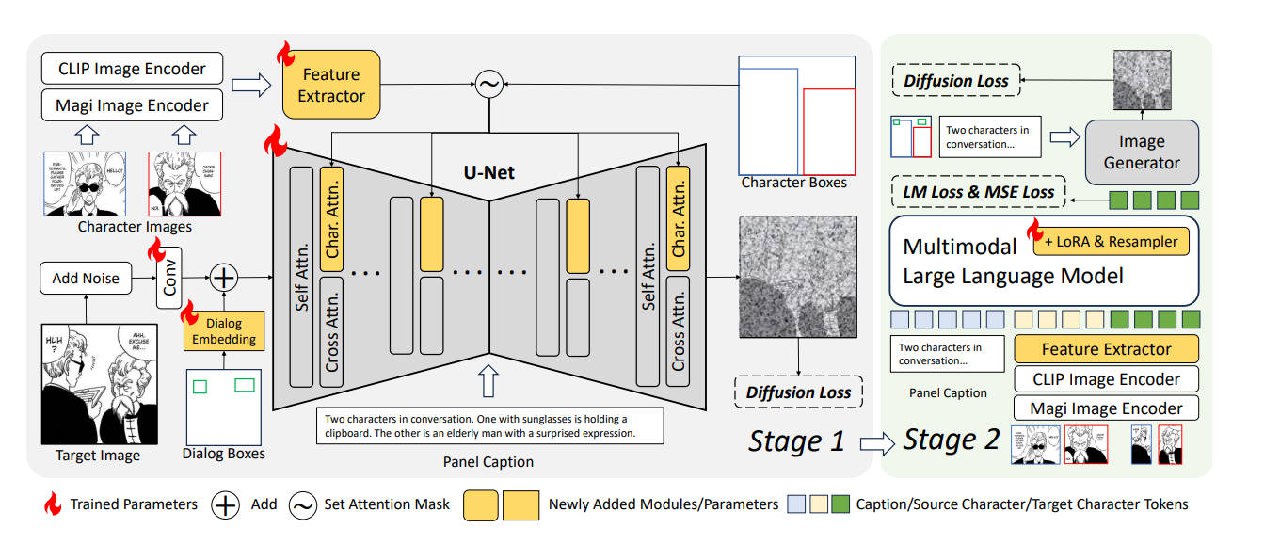
子模块
Motivation
- 避免复制粘贴效果:通过将角色图像特征转换为标记,防止直接从源图像复制像素细节。
- MLLM作为角色适配器:使用MLLM接收源角色特征和面板标题,生成与文本兼容的目标角色特征。
- 布局控制:采用轻量级的掩码编码技术,减少计算成本,同时保持高精度。
多角色特征提取
- 特征提取:CLIP&Magi, 提取局部和图像级特征。
- 特征处理:通过重采样模块处理特征,将角色图像压缩成少量标记,避免编码细粒度空间特征。
掩码交叉注意力注入
- 角色布局控制:通过复制键和值矩阵创建独立的角色交叉注意力层,应用掩码交叉注意力注入机制控制角色布局。
对话布局编码
- 对话嵌入:引入可训练的嵌入表示对话布局,通过掩码与噪声潜在相加,编码对话位置。
MLLM作为文本兼容的角色特征适配器
- 动态角色调整:MLLM允许基于文本提示动态修改角色状态。
- 损失函数:计算LM Loss、MSE Loss和扩散损失,以训练MLLM并确保编辑后的角色特征与图像生成器对齐。
两阶段训练
Stage 1:图像生成器训练 - SDXL
- 初始化模型
- 图像编码器:CLIP & Magi
- 特征提取器:IP-AdapterPlus-SDXL
- 图像生成器:SDXL
- 训练
- 使用1e-5的学习率训练SDXL
- 训练250K步
Stage 2:MLLM LoRA 微调
- 初始化
- 图像生成器:SDXL
- MLLM: SEED-X
- 训练
- 使用1e-4的学习率训练MLLM
- 训练20K步
- LoRA-Rank为64
- 仅训练LoRA和重采样器
评估
- 评估数据集 MangaZero、Manga109
- 自动化评估指标
- Fréchet Inception Distance得分(FID)
- CLIP Score
- DINO图像相似度(DINO-I)
- DINO角色图像相似度(DINO-C)
- 对话边界框F1得分
- 人类评估维度
- 文本-图像对齐
- 风格一致性
- 角色一致性
- 图像质量
- 总体偏好
- 对照组
- StoryDiffusion
- AR-LDM
- StoryGen
- SEED-Story
- MS-Diffusion
StoryDiffusion是一种无需训练的方法。我们直接使用在MangaZero上微调的SDXL文本到图像模型进行评估。
尽管如此,我们重新训练了其他基线模型,以在我们的数据集上进行公平比较。(这种方式是否科学,存疑!)
Q7:效果如何?结论是什么?
- DiffSensei在五个自动化指标上一致性地超越了基线模型
- 在多个维度上获得了人类评估者的最高评分,特别是在总体偏好、角色一致性和图像质量方面
Q8:下一步优化的方向是什么?
文中没有提下一步方向,但这个模式过于复杂了,是否能够简化,使用MLLM来统一实现特征提取器。而且基于的是SDXL,对于文字的表现能力其实难讲,如果能基于FLUX开发可能会更好。