Emu Series (Emu1 ~ Emu3)
BAAI - Emu系列简介
Emu Series (Emu1 ~ Emu3)
Beijing Academy of Artificial Intelligence (BAAI) 北京智源
Emu1 (202307) - Generative Pretraining in Multimodality(Arxiv)
Emu2 (202312) - Generative Multimodal Models are In-Context Learners(Arxiv)
Emu3 (202409) - Next-Token Prediction is All You Need(Arxiv)
Intro
Emu系列是专注于多模态大模型生成领域的,和上一篇LLaVA专注于多模态内容理解不同。
Emu起步算是比较早的,再之前就是Deepmind的Flamingo.
Emu能力覆盖:图生文、文生图、视频理解、多模态上下文生成、多模态对话等多模态任务。
Emu 创造性地建立了多模态统一学习框架与视频数据的大量采用,最终得以实现对任意形式的多模态的上下文序列进行图文任意模态的补全,即对于任意模态进行下一步自回归预测。
Emu1
发表时间:202307
模型架构:VisualEncoder(CLIP)、Adapter、LLM、VisualDecoder(SD1.5)
模型大小:总大小14B,其中LLM 13B
特殊标识:
- 图片特征序列开始和结束设计有特殊Token,[IMG]和[/IMG]
- 文本特征序列开始和结束设计有特殊Token,[s]和[/s]
训练数据:图片文本对,视频文本对,交错图片文本对,交错视频文本对
损失计算:
- 文本Token:下一个Token的交叉熵损失
- 图片Token:L2损失
多阶段训练:
- 预训练阶段
- 第一阶段:仅使用文本和图像数据
- 第二阶段:文引入视频数据
- 微调阶段:
- 视觉生成部分:高质量数据微调和DPO
- 视觉理解部分:图像到文本的训练和指令微调

Emu2(相当于Emu1的升级版)
发表时间:202312
模型架构:VisualEncoder(CLIP-plus)、Adapter、LLM、VisualDecoder(SDXL)
模型大小:总大小37B,其中LLM 34B
特殊标识:
- 图片特征序列开始和结束设计有特殊Token,[IMG]和[/IMG]
- 文本特征序列开始和结束设计有特殊Token,[s]和[/s]
训练数据:图片文本对,视频文本对,交错图片文本对,交错视频文本对
损失计算:
- 文本Token:下一个Token的交叉熵损失
- 图片Token:L2损失
多阶段训练:
- 预训练阶段
- 第一阶段:仅使用文本和图像数据, image_size 224*224
- 第二阶段:引入视频数据, image_size 448*448
- 微调阶段:
- 视觉生成部分:高质量数据微调和DPO
- 视觉理解部分:图像到文本的训练和指令微调
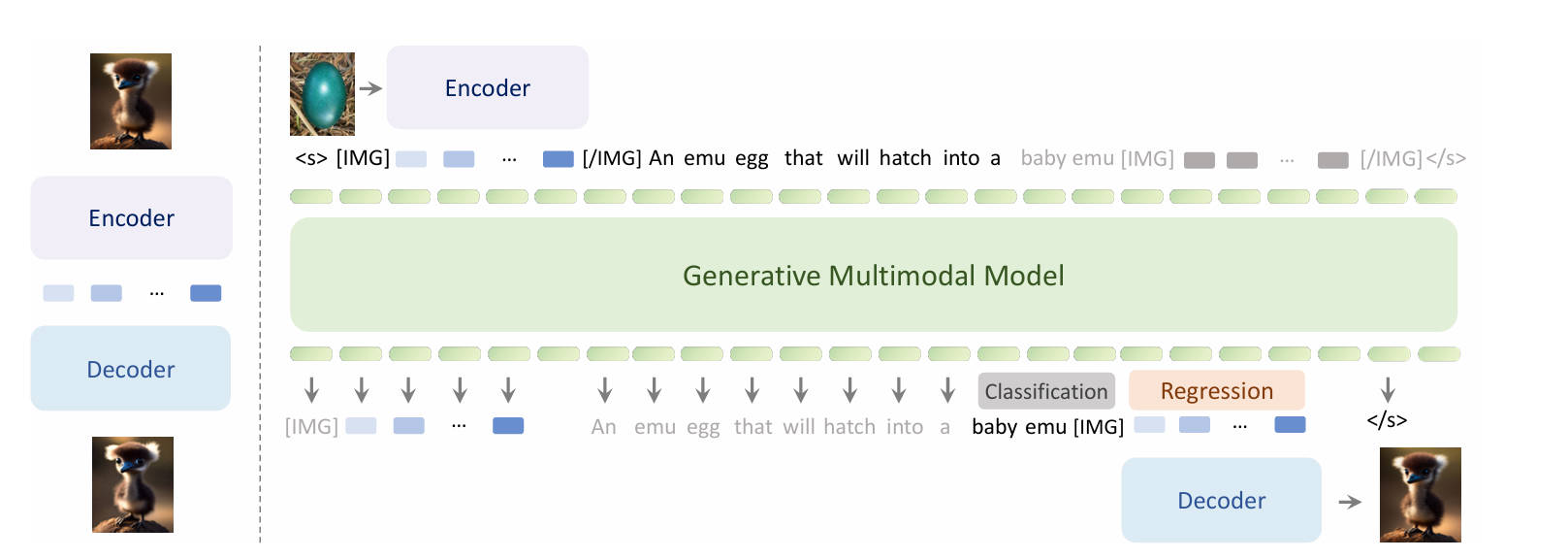
Emu3(统一多模态大模型)
发表时间:202409
模型架构:MLLM,从头开始训练的单一Transformer模型
模型大小:总大小8B
视觉Tokenizer: 将4x512x512的视频或512x512的图片转换为4096个离散Token;然后从大小为32768的词汇表中选择最相似的Token。
特殊标识:
- 图片特征序列开始和结束设计有特殊Token,[IMG]和[/IMG]
- 文本特征序列开始和结束设计有特殊Token,[s]和[/s]
训练数据:图片文本对,视频文本对,交错图片文本对,交错视频文本对
损失计算:下一个Token的交叉熵损失;为防止视觉标记占主导,引入0.5的权重
多阶段训练:
- 预训练阶段
- 第一阶段:仅使用文本和图像数据, image_size 224*224
- 第二阶段:引入视频数据, image_size 448*448
- 微调阶段:
- 视觉生成部分:高质量数据微调和DPO
- 视觉理解部分:图像到文本的训练和指令微调
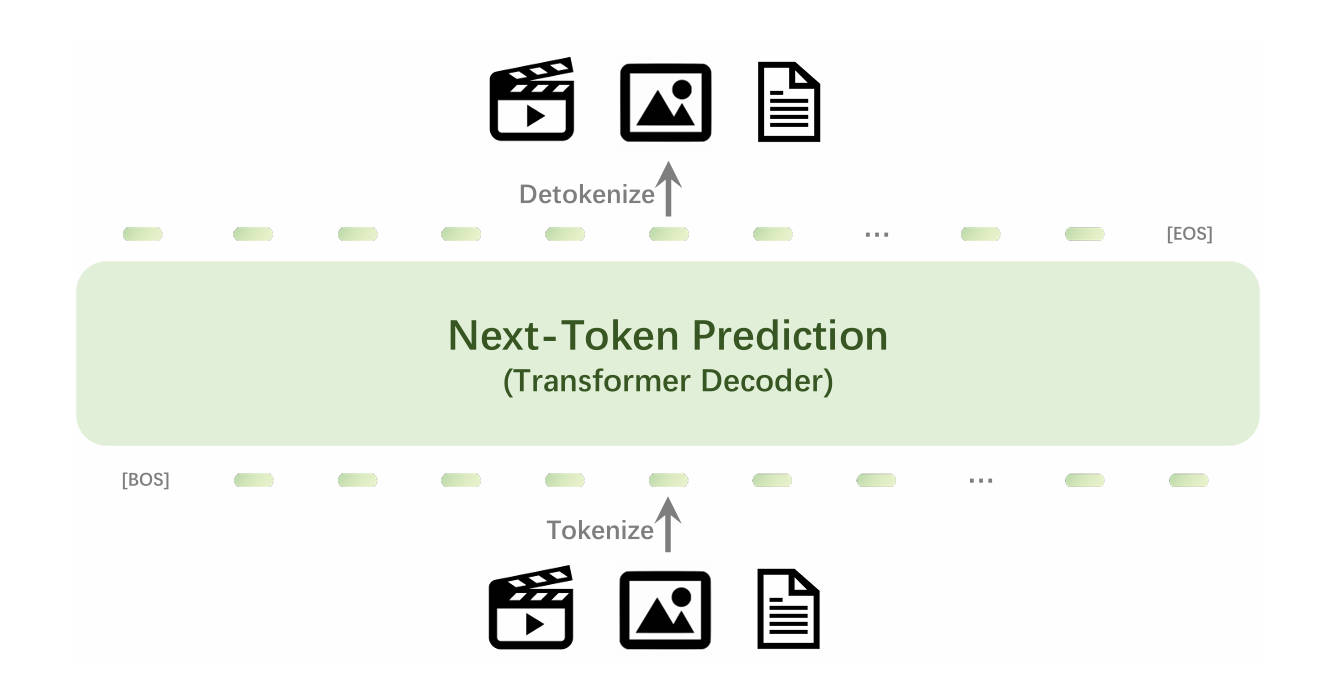
Question List
- Q1:
Answer
References
This post is licensed under CC BY 4.0 by the author.