A comprehensive review of research papers in the field of novel generation. - 202412
粗读,汇总目前收集到的关于Novel Generation的论文【截止202412】
Summary - Papers Worth a Deep Read
共31篇论文,从中筛选13篇值得精读的论文。
Outline Generation
- DOC:详细大纲控制
- RECURRENTGPT: 递归生成长文本
- Improving Pacing: 改进节奏
Plot Generation
- MoPS: 结构故事设定,创造情节
- SWAG: 故事情节搜索
- WHAT-IF: 探索分支叙事,互动小说,元提示
- Suspenseful Stories: 悬疑故事
Long-form Story Generation
- DOME: 长故事生成,叙事框架结合知识图谱
- Dramatron: 分层故事生成, 人工介入
Training
- LongWriter: 长故事生成, 训练GLM-9B
- Weaver: 写作专属模型
Prompt Tricks
- Reflections & Resonance: 多Agent,反思与共鸣
- Meta-Prompt: 元提示, Fresh-eye(子任务只能看到有限提示)
LongStory
论文:LongStory: Coherent, Complete and Length Controlled Long story Generation
2023.11
BERT时代的语言模型,基于BART训练,早过时了,不知道为什么会发表这么晚。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
**问题**
由于上下文窗口限制,长文本生成通常采用递归段落生成方法来组成长故事;这种方法存在上下文遗忘,导致连贯性问题出现;同时LM倾向于在递归生成中重复相同的故事,导致重复性问题。
挑战实现100~10K的长文本生成。
**方法**
Coherent, Complete and Length Controlled Long story Generator,两个创新点:
- 长短期上下文权重校准器(CWC),使用BERT-Tiny实现
- 长故事结构位置(LSP),即段落的顺序,为故事生成器提供段落的结构位置信息(例如,<front>、<middle>、<ending>、<next is ending>)
- 基于Transformer Encoder-Decoder框架,基于BART进行训练
- 基于GPT-2评估连贯性
- 基于n-gram BLEU评估重复性
-
**效果**
- 能降低重复性,及对多样性有效
- 连贯性、完整性、相关性优于基线模型
- 提升相关性并不总是能提升连贯性和完整性
E2E PLOT GENERATOR
论文:END-TO-END STORY PLOT GENERATOR
2023.10
整体效果难讲,就是微调Llama2-7B
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
**问题**
解决当前使用LLM生成情节的几个问题:
1. 调用LLMs次数多,昂贵且耗时
2. 情节框架太死,不能个性化
**方法**
1. OpenPlot: Prompt + LLAMA2 生成13K故事情节,基于Llama2-13B-chat
2. E2EPlot: 使用13K数据,通过SFT训练,基于Llama2-7B-chat
3. RLPlot: 使用RLHF微调E2EPlot
4. GPT-4量化评估
**效果**
- 生成速度:1K Token/30s
- 质量: 与DOC/OpenPlot相当
Arbitrary Writing Styles
论文:Learning to Generate Text in Arbitrary Writing Styles
2023.12
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
**问题**
LLM模仿著名文家作家的风格非常容易,但如果想通过instruction或ICL来模仿特定作者的风格会比较难。特别是一些风格或写作习惯,即使是语言学家也很难描述。
**方法**
STYLEMC: 由LLM和Regressor组成,Regressor经过风格训练,在LLM推理时,重调其概率分布,使输出更符合指定风格。
LLM:MPT-7B
Regressor: OPT-1.3B
**作者风格
**效果**
- 可以捕获直观的风格特征
- 可以作为一种有效作者匿名化技术
- 在零样本设置中,相比LLM更难被检测为AI生成,作者归因于更好地模仿了人类写作风格的能力
- 开源了模型、数据集、训练脚本
Suspenseful Stories
论文:Creating Suspenseful Stories: Iterative Planning with Large Language Models
2024.02
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
**问题**
悬疑故事是小说中的一种常见类型,但在AI中很少被探索,因为很难生成悬念。
本文探索基于迭代提示规划方法、以及认知心理学和叙事学中的悬念理论,实现完全零样本的自动化悬疑故事生成。
关于悬念的心理理论:
当读者相信主角面临负面结果,并且逃避即将到来的负面结果的可行手段的数量或质量已经减少时,读者会感到悬念。
具体方法:
1. 我们建立了一个有目标的主角和一个如果失败就会发生的负面结果。
2. 我们提示LLM考虑主角可能实现目标的不同方式。
3. 然后,我们通过在故事世界中建立条件来对抗这些计划,这些条件将使主角的计划失败。
4. 重复这个过程几次,就可以产生故事的大纲,然后我们将大纲详细扩展成长文本序列
**方法**
1. 背景设置(主角、目标、负面结果):我们然后使用LLM生成一个如果主角不能实现目标,主角将被置于的可怕情况
2. 大纲规划:迭代生成
a. Prompt1:生成一系列主角可能采取的行动
b. Prompt2:对每个行动,生成潜在原因,导致行动失败; 形成行动-原因对(action-reason pairs)
c. Prompt1 <--> Prompt2 迭代生成
d. 在最后一次生成时,允许主角成功
3. 故事生成:迭代生成
a. 将每一个action-reason对,转换为简短的摘要
b. 基于摘要,生成一系列事件;事件可以作为每个故事章节的大纲
c. 使用LLM详细描述每个事件的细节
**理论**
- 悬念理论:当读者相信主角面临负面结果,并且逃避即将到来的负面结果的可行手段的数量或质量已经减少时,读者会感到悬念。
在第一种模式中,我们提前揭示了主角行动将失败的原因,为读者设置了一个主角不知道的失败预期,因此不太可能能够避免。例如,如果我们的主角是一个间谍,他们可能不知道对手已经设下了陷阱。
- 叙事理论的知识差异:
我们在事后揭示信息,向读者解释主角的行动从一开始就注定要失败

SWAG
论文:SWAG: Storytelling With Action Guidance
2024.02
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
**问题**
人们通常使用LLM进行一次性创作,能够产生连贯但不一定吸引人的故事。
如何生成有连贯且有趣的长篇故事?是一个重大挑战。
**假设**
将故事讲述结构化为一个搜索问题。
即,在给定故事创意的条件下,在可能的故事的搜索空间中找到"最优路径"。
构建两个模型,反馈循环:
- 故事内容模型:根据选定的Action,生成故事
- 下一步最佳Action:辅助LLM,确定在故事的当前状态下下一个最佳Action
**方法**
主要组件:
- 故事生成模型:SWAG允许使用任何开源LLM或LLM服务进行故事生成。
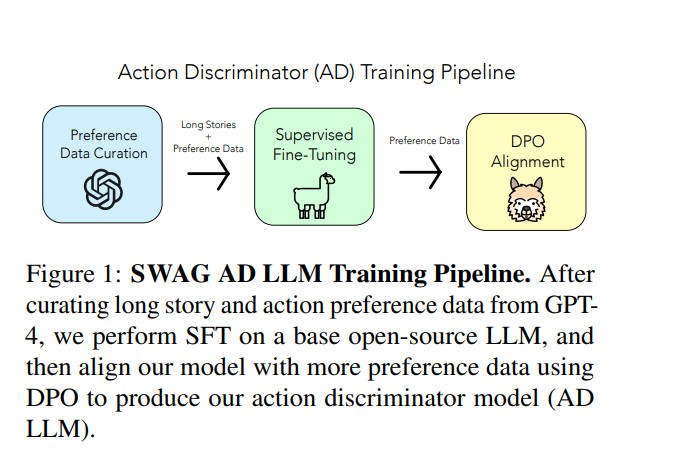
- 行动鉴别器模型:我们通过收集故事动作的偏好数据,并使我们的偏好数据集与预训练的LLM对齐,来创建AD LLM。
训练流程:
1. 收集偏好数据:收集故事动作的偏好数据,学习如何选择故事下一部分的最佳动作。
- 使用GPT-4生成数据:在给定"故事状态"的情况下选择下一个最佳动作
- 定义故事状态为X = (P, S, A),其中P是故事提示,S是故事提示的当前延续,A是为发展故事下一部分而采取的下一个"动作"。
- 20K 长故事:使用LLaMA2-7B、Mixtral-8x7B,使用Prompt生成多样化样本
- 32K context:微调Mistral-7B, 以支持长上下文
- 25K 偏好数据:DPO训练偏好模型
2. SFT LLM: 两阶段SFT&DPO。
Phase 1:我们在长故事数据集上微调AD LLM。我们训练模型以接受提示作为输入并生成长上下文故事。
Phase 2:我们在带有被选择和被拒绝动作的偏好数据集上微调(DPO)我们的新长上下文AD LLM。
Phase 3:使用LongLoRA 来扩展上下文长度。
3. 耗时:
- SFT:8xA100 36H
- DPO:8xA100 12H
**推理流程**
推理流程涉及两个主要模型:动作鉴别器(πAD)和故事生成模型(πstory)。这两个模型通过一个反馈循环相互协作,以生成故事。以下是推理流程的详细步骤:
1. **初始段落生成**
从故事提示(P)开始。
使用故事生成模型(πstory)根据故事提示(P)写出故事的初始段落(S(0))。
2. **初始故事状态**
形成初始故事状态X(0),包含故事提示(P)、初始段落(S(0))和空动作(∅)。
3. **动作选择**
将初始故事状态X(0)输入到动作鉴别器模型(πAD)。
πAD根据当前故事状态和一系列预定义的可能动作,选择下一个最佳动作(A(0))。
4. **故事发展**
更新故事状态X(0),加入选定的动作(A(0)),形成新的故事状态X(0) = (P, S(0), A(0))。
5. **迭代过程**
重复以下步骤,直到达到所需的故事长度:
a. 使用故事生成模型(πstory)根据当前故事状态(X(i-1))生成故事的下一个段落(S(i))。
b. 使用动作鉴别器模型(πAD)根据更新后的故事状态(X(i))选择下一个最佳动作(A(i))。
c. 更新故事状态X(i),加入新的动作(A(i)),形成新的故事状态X(i) = (P, S(i), A(i))。
6. **故事输出**
经过k次迭代后,输出最终的故事S(k)。
通过这个迭代的反馈循环,SWAG方法能够结合两个模型的优势,生成既连贯又引人入胜的长篇故事。这个过程可以灵活地使用不同的LLMs,无论是开源还是闭源,以适应不同的内容生成需求。
**Action Space**
Our action space consists of the following 30 phrases:
"add suspense", "add action", "add comedy", "add tragedy", "add romance",
"add mystery", "add conflict", "add character development", "add plot twist",
"add dialogue", 'add fantasy elements", "add historical context", "add science
fiction elements", "add horror", "add magical realism", "add philosophical
themes", "add satire", "add foreshadowing", "add a flashback", "add a dream
sequence", "add symbolism", "add irony", "add allegory", "add a cliffhanger",
"add a moral dilemma", "add a subplot", "add an antagonist", "add setting
details", "add cultural references", and "add humor".
These actions are generated via prompting GPT-4,
with the goal of obtaining more abstract actions forstory guidance.
Future work may focus on more fine-grained action generation.
Weaver
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
**问题**
内容风格过于平淡
文风过于"GPT"
预训练文本通常为WEB- data(高质量内容占比不到0.1%),在建模了这些数据分布后,通常倾向输出普通的内容。这个问题通过RLHF无法解决,只能缓解,矮子里面拔将军。
**假设**
增加高质量样本,进行继续预训练。
包含完整Pipeline:继续预训练 --> SFT --> DPO
**数据**
1. **预训练数据-200B**
从开源预训练数据中,筛选高质量小说、短故事、创意文案等,以及私有小说、短文数据;
2. **SFT数据-100K**
参考Meta的**LongForm**和**HumpBack**方案,构建基于一段高质量内容,自动生成高质量输出的Pipeline。包括以下Instruction:写内容、写大纲、扩写、润色、精简、风格迁移(仿写)、审校、头脑风暴、起标题、写作相关对话。
"""标注 Prompt 中首先解释任务的定义和几个输入输出样例,之后给出一个从一段文本中自动挖掘润色任务指令 / 输入 / 输出的例子和标注的思考过程: "首先在文本中找到一段写的很好的句子,假设这句话是经过一次润色而来的,之后猜测在润色之前这句话会是什么样子,最后分析润色前后的变化,推理出润色的指令会是什么样子。" 之后标注的 Prompt 中输入需要标注的例子并指示大模型按照例子中的标注流程进行输出,最后 parse 出模型输出中标注的 "指令 / 输入 / 输出" 部分,组合成一条写作指令数据。"""
3. **DPO数据**
使用**Constitutional DPO**技术,基于原则高效将模型和专业作者对齐的方案。
"""Constitutional DPO 以人类创作者创作的高质量的输出作为正样本,利用人类作家 / 编辑整理提炼出的各个领域写作的 "原则 (Principles)",用这些原则去生成能够教会模型更好地遵守这些原则的负样本。具体来说,专业作家 / 编辑首先整理出四大领域十个任务中,好的内容需要遵循的共 200 余条原则。对于每一个原则,编辑总结出原则的详细解释和一对符合 / 违背该原则的例子,并用几句话解释出符合 / 违背原则的原因。之后,对于每一个正样本,负例生成的 prompt 中首先展示出领域 - 任务上的原则集合和原则对应的例子和解释,之后展示出正样本,要求大模型分析出正样本最符合哪几条原则,并推理出如何修改能够在作出较少改变的情况下让正样本转而违背这个原则,从而变成一条质量没那么好的输出。团队精选了各个领域高评分 / 高阅读量 / 高点赞评论数的内容作为正样本,通过 Consitutional DPO 的流水线生成出了数万条偏好数据 (preference data),并利用这些数据对模型利用 DPO 进行了对齐训练。"""
4. **RAG & Function Calling 数据**
检索增强生成(RAG)和函数调用策划指令数据,使Weaver能够利用外部知识和工具
**方法**
Models: MINI-1.8B、BASE-6B、PRO-14B、ULTRA-34B
Synthesis Data: LongForm、HumpBack
Expand Context:LongLoRA
DPO: Constitutional DPO
RECURRENTGPT
论文:RECURRENTGPT:Interactive Generation of (Arbitrarily) Long Text
2023.05
参考文献:https://www.zhihu.com/question/603600877/answer/3100979676
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
**问题**
由于Transformer的固定上下文长度,导致无法处理长文本。
**假设**
使用自然语言模拟LSTM中的长短时记忆机制,递归迭代式生成长文本。
**方法**
RecurrentGPT不是一种模型,而是Prompt Engineering的一种方法,类似CoT,但稍显复杂。
RecurrentGPT解决这个问题的核心思路是:在每一轮新对话中,额外将之前的一些关键信息输入给LLM,让它知道之前写过什么。
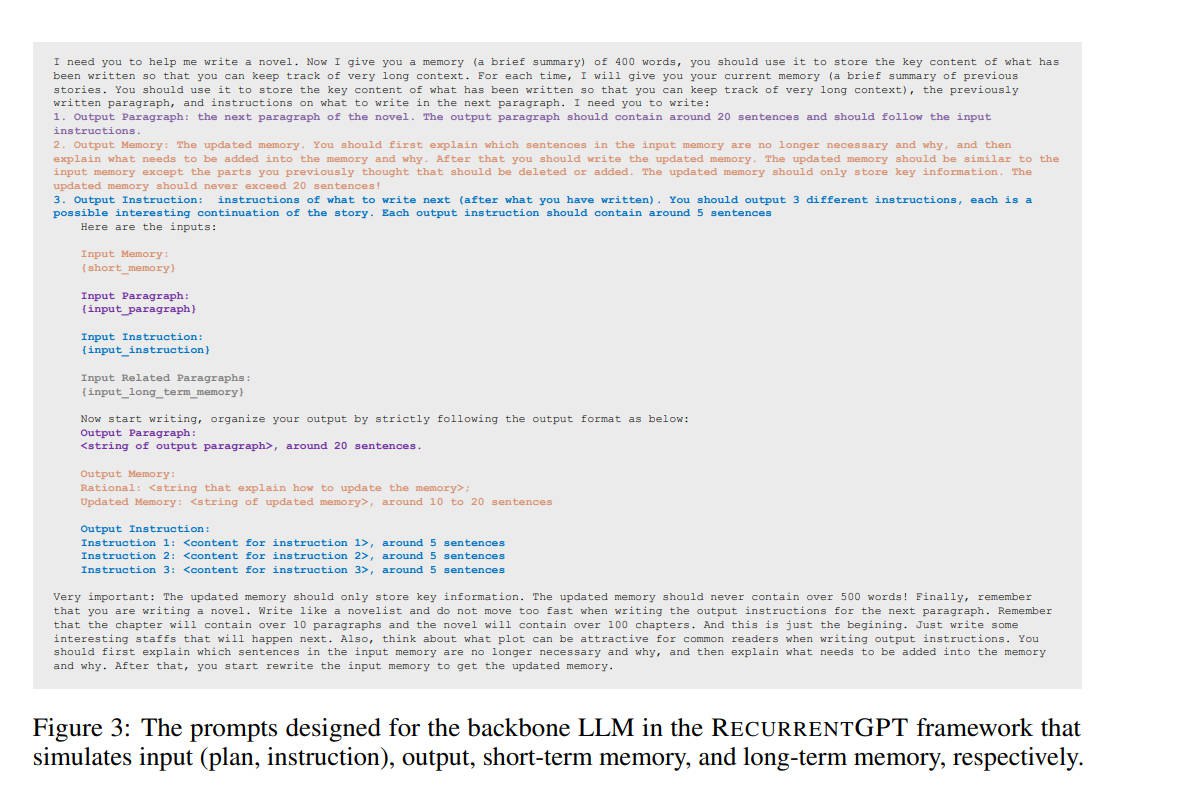
RecurrentGPT定义了一个Prompt模板,模板分为三个部分(参见图1,细节后文详述):
**指令(Instruction)**:用来告诉LLM模板的格式和各种注意事项。它的主要作用是让LLM理解模版中各部分内容。
**输入(Input)**:用来在每一轮对话中向LLM输入一些写作所需要的信息。
- **Input Paragraph**:它是上一轮对话中LLM输出Output部分中的正文内容,即Output Paragraph。
简单来说,Input Paragraph的作用就是告诉LLM它上一轮写的是什么。
- **Short-term Memory**: 包含之前写过所有内容中的一些关键信息的总结; "关键信息"是指对接下来写作有帮助的信息。
- **Long-term Memory**: 这里面包含的是与接下来写作有关的曾经写过的正文内容。
"""因为Long-term Memory的作用是为LLM提供与接下来写作有关的曾经写过的正文内容,而Short-term Memory中包含的又是与接下来写作有关的关键信息。
所以一种自然的做法是,利用Short-term Memory的每个句子,去VDB中寻找K个与之最相关的句子来作为Long-term Memory的内容。"""
- **Input Instruction**:它指明了下一轮对话中LLM应该生成的内容大纲。
**输出(Output)**:每一轮对话中LLM输出的内容。
- **Output Paragraph**:它是LLM在下一轮对话中输出的正文内容。
- **Output Memory**: 在Input中的Short-term Memory主要用来保存之前写过所有内容中的一些关键信息的总结。
这些"关键信息"是指对接下来写作有帮助的信息。而Output Memory可以理解为是对Short-term Memory的更新。
Output Memory的内容会直接作为下一轮对话的Short-term Memory来使用。
- **Output Instruction**:我们让LLM在写完正文后,会让它同时生成一个Instruction用来说明接下来的内容大纲。
Output Instruction就是下一次Input中的Input Instruction。
我们也可以让LLM生成多个Instruction,然后人工手动选择其中的一个,以此来控制故事发展的路线。
**效果**

我需要你帮我写一篇小说。
因为小说比较长,所以我会同你进行多轮对话来完成长文撰写。
在每一轮对话中,我会给你四部分输入信息。
第一部分输入信息是Input Paragraph,其中包含你上一轮写作中完成的正文内容。
你新写的内容需要与这部分内容衔接。
第二部分输入信息是Short-term Memory,其中包含你已经写过的内容的关键信息。
该信息主要帮助你在进行内容撰写时能知道之前写过的关键内容。
第三部分输入信息是Long-term Memory,其中包含你之前写过的一些正文内容。
这部分信息主要帮你回忆之前写过的正文。
第四部分输入信息是Input Instruction,其中包含你下一轮创作中所需要遵循的内容大纲。
每一轮对话中你需要完成的输出包括以下内容:
1. Output Paragraph:当前轮对话中你创作出的小说内容。
每一次输出大概20个句子。输出的内容不要太短。
2. Output Memory:用来更新下一轮的Short-term Memory。
根据你新写的内容,首先说明哪些在Short-term Memory中的句子不再需要,并给出原因。
然后说明哪些句子你认为需要新加入到Short-term Memory,并说明原因。
最后将你的改动后的内容写到Output Memory中。
注意,Output Memory中的内容应该与Short-term Memory非常相似。
你不应该擅自修改未删除的内容。
Output Memory中的内容不要超过20个句子。
3. Output Instruction:下一轮写作的内容大纲,内容大概需要与前文紧密联系。
你需要输出3个不同的内容大纲,每个大纲大概三个句子。
注意,不同大纲之间没有顺序关系,它们是故事发展的不同路线。
你创作的内容主题是:
一个武侠小说。男主人公因为被冤枉而入狱。在狱中偶然结实一位神秘人,进而习得绝世武功而成功复仇。
下面是你本轮创作的输入:\n
Input Paragraph:\n
{input_paragraph}\n
Short-term Memory:\n
{short_term_memory}\n
Long-term Memory:\n
{long_term_memory}\n
Input Instruction:\n
{input_instruction}\n
现在你可以开始写作了。请将你的写作输出内容严格按照以下格式进行组织:\n
Output Paragraph:\n
Output Memory:\n
Rational: <此处详细解释你更新下一轮的Short-term Memory的方法。
包括哪些句子不再需要,并说明原因;哪些句子需要添加进去,并说明原因。> \n
Updated Memory: <更新后的Short-term Memory> \n
Output Instruction:\n
Instruction 1: <此处替换为你输出的故事大纲1,大概包含5个句子。> \n
Instruction 2: <此处替换为你输出的故事大纲2,大概包含5个句子。> \n
Instruction 3: <此处替换为你输出的故事大纲3,大概包含5个句子。> \n
最后再强调一些重要事项:Updated Memory中只需要保存最为关键的信息。
Updated Memory中最多只能包含500个字。
在首轮对话中,你只会有关于故事主题的输入。因此你无需解释需要从Short-term Memory中删除什么内容。
请严格按照输出格式进行内容输出,只包含Output Paragraph、Output Memory和Output Instruction部分。
请牢记,你在写长篇小说。
请像一个职业小说家一样写你的小说。
这本小说需要逐字逐句去书写,内容不能太跳跃。
故事需要一步一步去缓慢推进。
所有发生的细节都要一一详细描述。
StoryVerse
论文:StoryVerse: Towards Co-authoring Dynamic Plot with LLM-based Character Simulation via Narrative Planning
2024.05
游戏领域,自动化剧情,角色互动
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
**问题**
游戏剧情,对于玩家体验非常重要,玩法、剧情、特效是游戏的核心。
传统游戏剧情:采用符号叙事规划方法,需要大量的知识工程,限制了剧情的规模和复杂性。
LLM驱动NPC:允许剧情从角色与环境的互动中自然产生;但是,这种去中心化剧情生成的紧急性质使得作者难以指导剧情进展。
**假设**
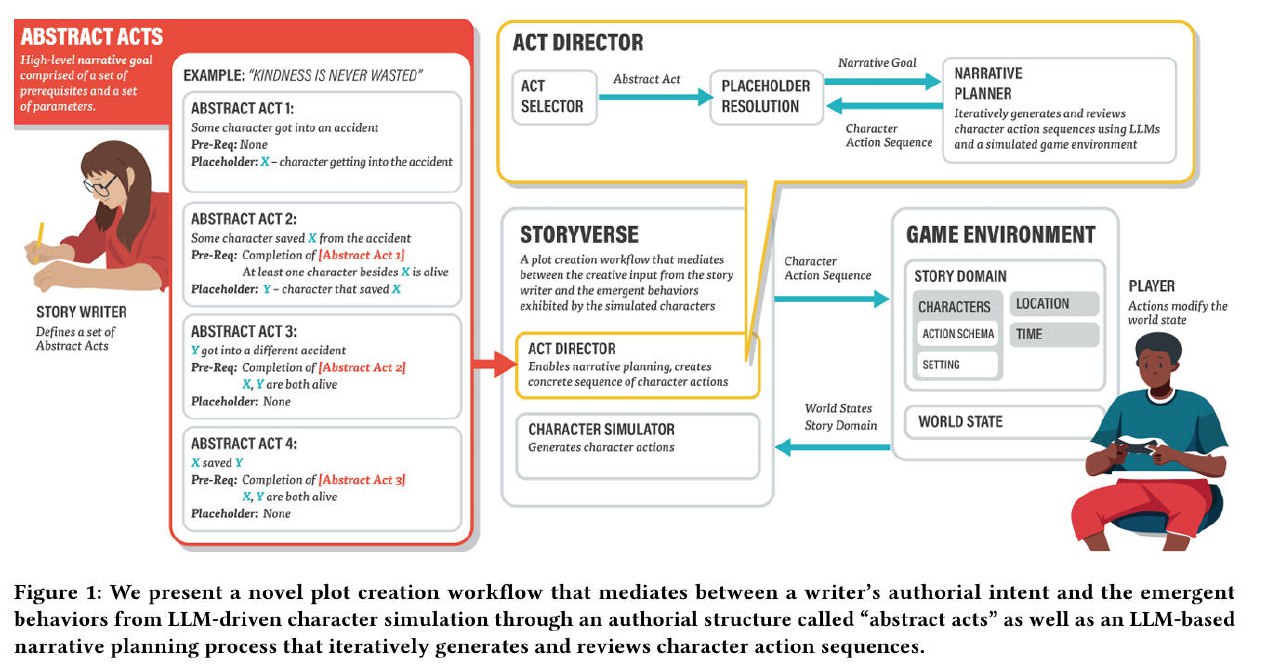
**一种新颖的剧情创建工作流程**
通过一种新颖的作者结构称为"抽象行为"和基于LLM的叙事规划过程,协调作者的创作意图和LLM驱动的角色模拟的紧急行为。
作者定义高级剧情大纲,这些大纲后来通过基于游戏世界状态的LLM基础叙事规划过程转化为具体的角色行动序列。
该过程创建了"活生生的故事",这些故事能够动态适应各种游戏世界状态,从而实现作者、角色模拟和玩家共同创造的叙事。
**整体流程**
StoryVerse,一个使用基于LLM的叙事规划和角色模拟来生成动态故事的系统。
1. 作者不是直接指定角色的行动来干预角色模拟,而是定义高级剧情大纲作为抽象行为,这些行为后来通过Act Director组件"实例化"为具体行为。
2. 在实例化一个抽象行为时,Act Director考虑到游戏世界的状态、之前的行动和由正在进行的LLM驱动的角色模拟器组件产生的角色行动。
3. 产生的具体行动包含一系列角色行动,可以在游戏环境中执行以更新世界状态,从而通知后续的角色模拟和后续的行动。
**方法**
我们的工作基于游戏中由LLM驱动的角色模拟。目标是创建一个新流程,让故事作者能够指导剧情发展,同时允许剧情细节自然产生。
**工作流程**
1. 整合组件:系统包括三个主要部分:Act Director、角色模拟器和游戏环境。
2. 作者输入:作者提供高级剧情大纲,称为"抽象行为"。
3. 实例化行为:Act Director根据游戏世界状态将抽象行为实例化为具体角色行动。
4. 角色行动生成:如果作者没有输入,角色模拟器默认生成角色行动。
5. 游戏环境执行:游戏环境执行角色行动并更新世界状态。
6. 玩家干预:玩家可以通过行动改变游戏世界状态,影响剧情进展。
**抽象行为**
- 定义高级剧情目标和转折点。
- 包含先决条件,决定何时执行行为。
- 使用占位符,允许剧情根据玩家行动和角色模拟动态变化。
**Act Director**
- 评估抽象行为是否满足执行条件。
- 生成具体角色行动序列(叙事计划)。
- 通过LLM迭代改进计划,确保剧情连贯性和执行可行性。
**实施**
- 我们实现了一个基础的LLM角色模拟器和游戏环境代理。
- 使用提示链技术和少量示例提高LLM输出质量。
- LLM(gpt-4-0125preview)用于所有实验。

LLM Fall Short - Complex Relationships
论文:Large Language Models Fall Short: Understanding Complex Relationships in Detective Narratives
2024.02
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
**问题**
现有的叙事理解数据集往往未能表现出现实生活中社会场景中关系的复杂性和不确定性。
**假设**
引入了一个新的基准测试,Conan,旨在从侦探叙事中提取和分析复杂的人物关系图。
设计了层次化的关系类别,并从不同角色的角度手动提取并标注了以角色为导向的关系,
包括大多数人物所知道的公共关系和只有少数人知道的秘密关系。
三个子任务:
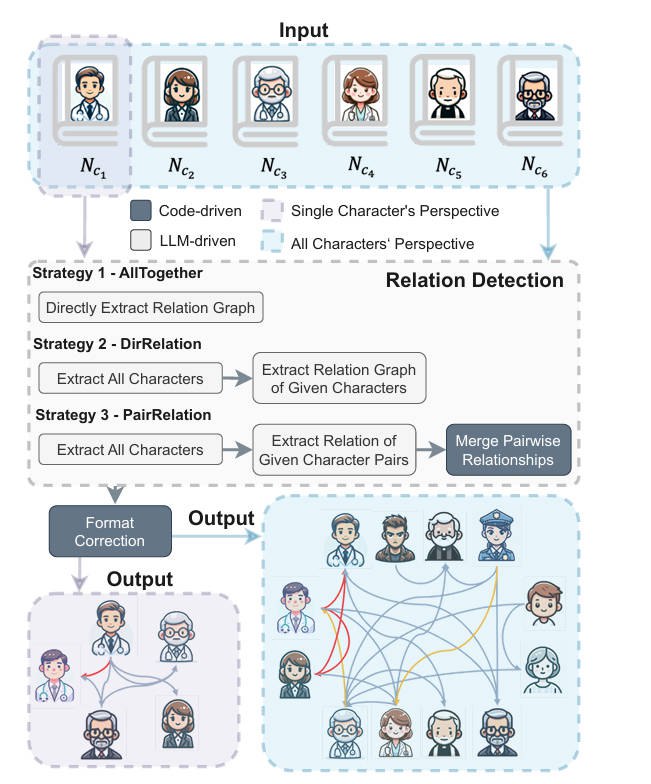
1. 角色提取: 识别给定故事中的所有角色,可以是 Nci 或 N。
2. 实体链接:从特定角色 ci 的视角识别角色之间的关系。这在形式上等于 RC|Nci。
3. 关系推断:通过考虑所有以角色为中心的叙事来推断角色之间的实际关系。在形式上,这对应于 RC|N。
挑战:
1. 一个角色可能有不同的身份或别名,这些身份可能在故事的不同点出现。
2. LLMs 在基于现有信息进行基本推断时存在困难,这种现象被称为"反转诅咒"。
例如,当我们知道 A 是 B 的父亲时,根据这些模型,并不一定意味着 B 就是 A 的孩子;涉及从多个角色的视角进行推断,这些视角有时会产生冲突或不一致的信息。
**数据**
1. 构建层次化关系结构:5个顶级类别、54个中级类别、163个详细类别
2. 标注:由四名粉丝完成
a. 角色提取:识别所有角色
b. 实体链接:识别角色之间的关系,以三元组形式
c. 冲突检测和关系细化:形成统一的关系图
3. 数据集:100个故事,每个故事大概27Ktoken,共产生8K个标注样本
**效果**
使用F1指标评估
**后续方向**
1. Conan可以用于评估LLMs理解复杂角色关系的能力
2. 增强LLMs推理能力、优化信息管理能力(例如,使用余弦相似度、RAG)来提升效果
CAT-LLM
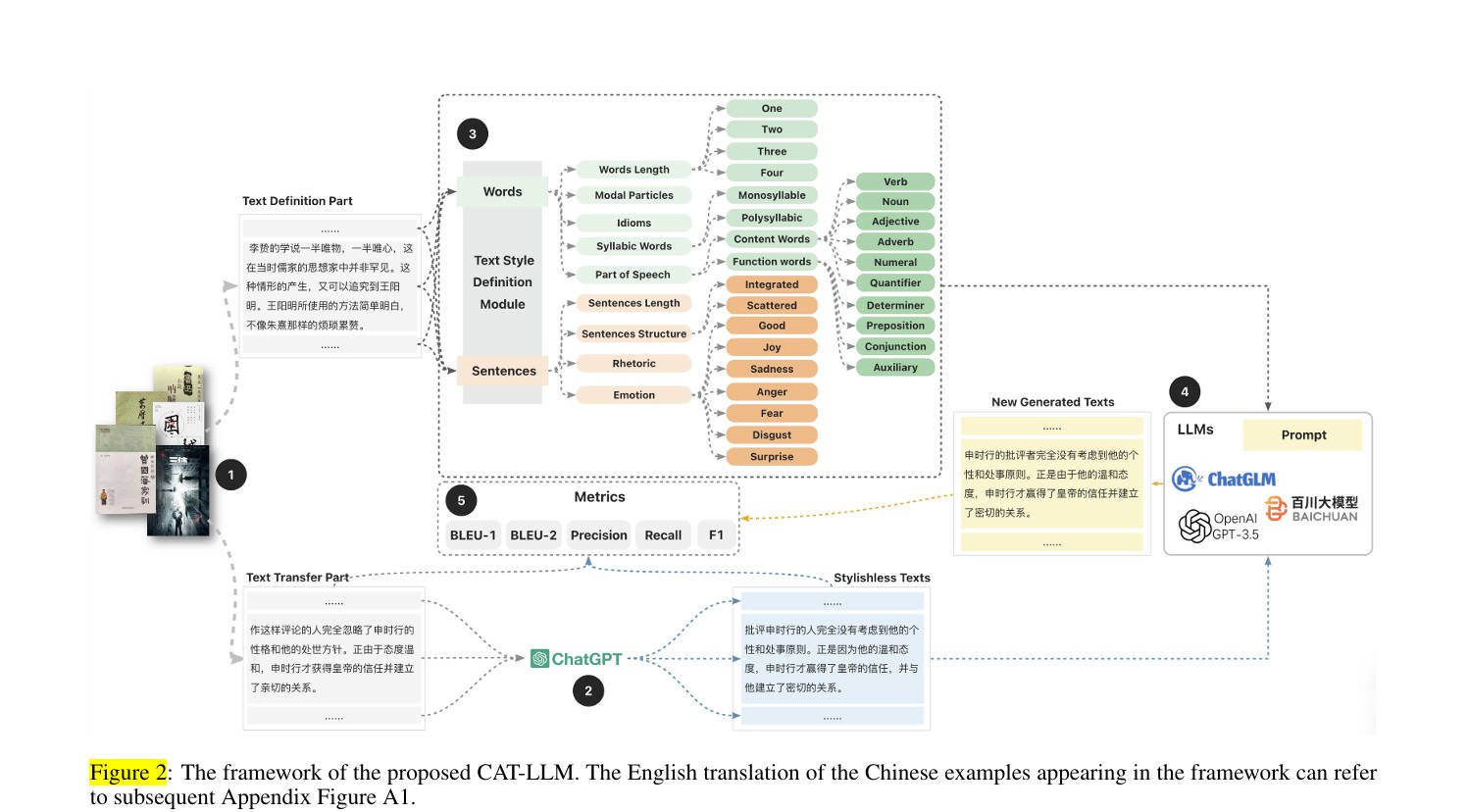
论文:CAT-LLM: Prompting Large Language Models with Text Style Definition for Chinese Article-style Transfer
2024.01
文本风格转换、中文领域
1
2
3
4
5
6
7
8
9
10
11
12
**问题**
现在研究英文短文本风格转换的比较多,中文领域研究较少,特别是长文本。
**假设**
一个基于LLMs的中文文章风格转换框架(CAT-LLM)。
首先,CAT-LLM结合了各种机器学习算法,全面学习文章风格,创建详细风格定义。
我们的分析侧重于单词和句子层面的风格,这不仅在学术上合理,而且易于理解。
然后,我们根据风格定义设计了风格增强提示,用于风格转换。
**效果**
如图,感觉过于复杂,不够优雅。可用性难讲

Outline-guided Text Generation with LLMs
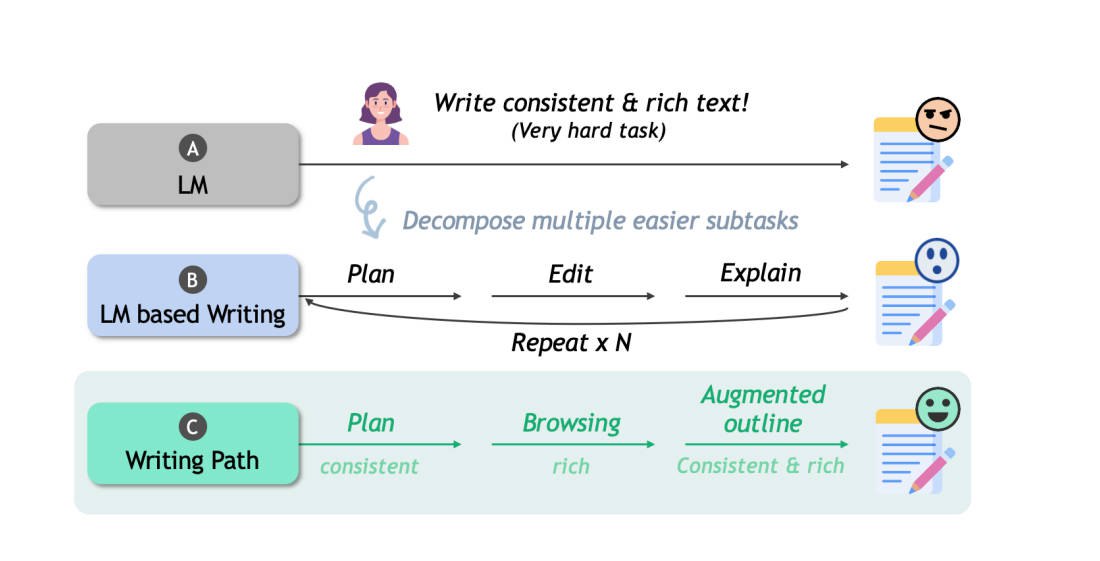
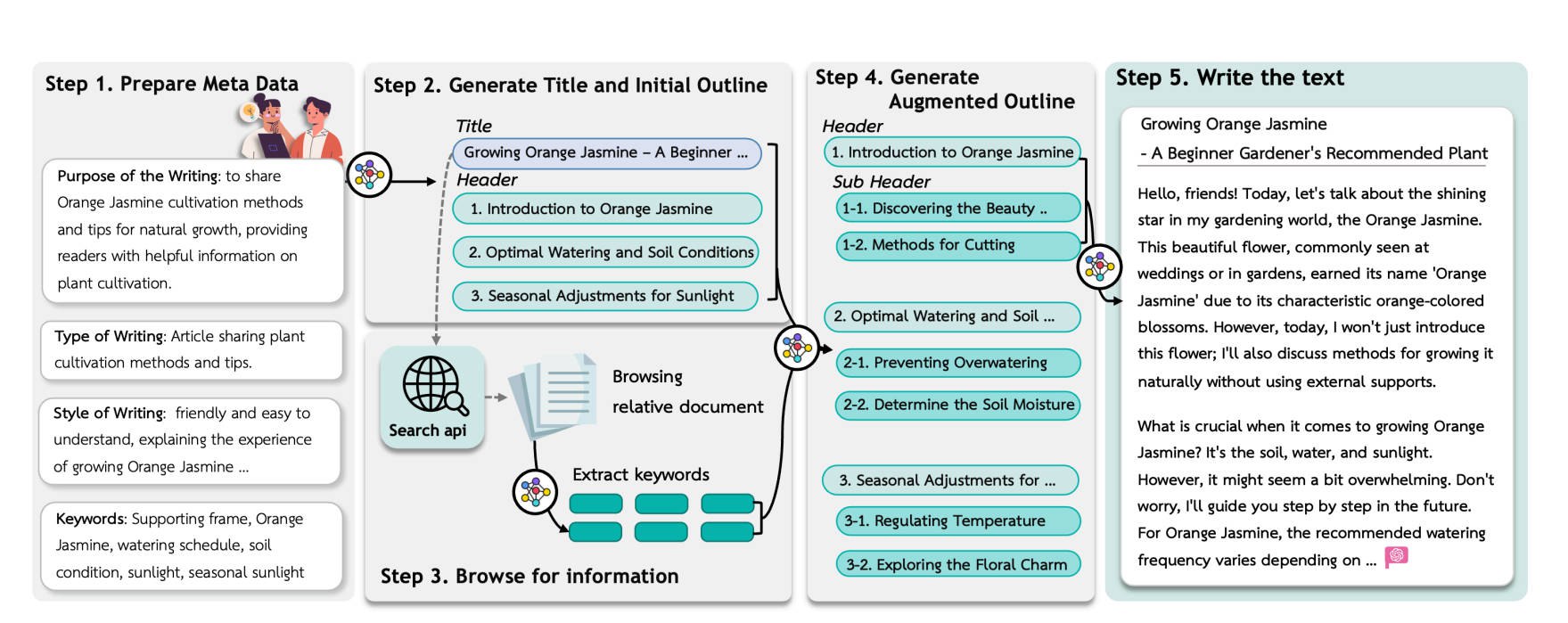
论文:Navigating the Path of Writing: Outline-guided Text Generation with LLMs
2024.04
主要用于博客写作,RAG增强,逐步完善
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
**问题**
在准确生成符合用户特定意图和要求的高质量内容方面,存在障碍。
**假设**
借鉴结构化写作计划以及CoT推理路径:
1. 收集用户想法,创建大纲
2. 通过信息浏览进一步增强初始大纲,添加更多信息
3. 构建多维写作评估框架评估中间和最终输出
**相关工作**
1. LLM in Writing: 提纲规划和草稿生成, 递归重提示和修订
2. 整合外部信息: RAG
3. 写作评估:使用**CheckEval**,通过为每个写作方面定制包含特定子问题的清单,我们提供了一种更可靠和准确的写作质量评估方法。
Improving Pacing
论文:Improving Pacing in Long-Form Story Planning
2023.11
控制大纲节奏
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
**问题**
LLM在生成长篇故事或大纲时,常常遇到不自然的Pacing问题,无论是忽略重要事件还是过度渲染无关紧要的细节,都会给读者带来突兀的体验。
例如:一些过于详细的章节感觉像是"艰难的跋涉",而在其他情况下,GPT-4会"用总结的方式快速掠过重大的重要时刻"
**相关工作**
1. **DOC**:将大纲转化为完整的故事,并且可以动态变化段落长度
**方法**
1. 训练详细性评估器:评估每个段落的详细程度
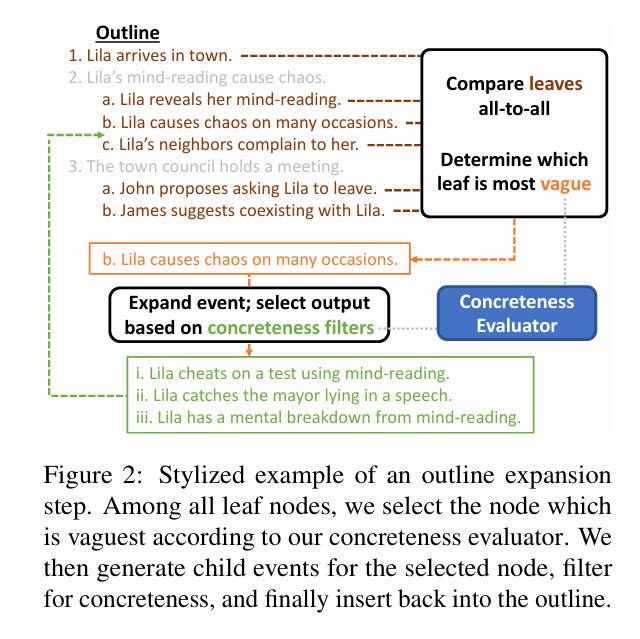
2. 大纲生成: 使用具体性评估器M来控制层次化大纲生成的节奏,确保故事节奏的一致性。
a. 高层次大纲结构:将层次大纲视为一个树形结构,根节点是故事前提,叶节点包含情节事件。
b. 最模糊优先扩展顺序:
i **选择最模糊节点:**在每个大纲扩展步骤中,计算每个叶节点相对于其他叶节点的具体性概率平均值,并选择最模糊的节点进行扩展。
ii **节点扩展:**选择最模糊的节点后,生成子事件(子节点)。
c. 具体子节点生成:
i **生成候选子节点:**使用ChatGPT提示,根据父节点及其祖先的上下文生成两个或更多的候选子节点。
ii **过滤子节点:**确保子节点与父节点不相似,且子节点比父节点更具体。
- **如果子节点与父节点过于相似,或者子节点的具体性低于阈值,将重新生成子节点。**
- **如果多次尝试后仍无法生成满意的子节点,将增加ChatGPT的温度参数并重新启动当前节点的扩展。**
MoPS
论文:MoPS: Modular Story Premise Synthesis for Open-Ended Automatic Story Generation
2024.06
情节合成 Modular Story Premise Synthesis (MoPS)
一个故事如果注定失败,那么问题往往出在选题/创意阶段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
**问题**
故事前提,包括:主要思想、基础信息和轨迹。在自动故事生成汇总充当初始触发器。
**获得故事情节**
现有工作主要有三种方法:
1. 数据集前提提取:从公共数据集中随机提取现成的故事前提
2. LLM前提诱导:利用模型的广泛知识来生成众多故事情节
3. 人为策划:依赖于人类提供或预定义的前提
现有的故事情节来源受到多样性不足、质量不均和成本高昂的限制,难以扩大规模。
前提就是你的故事是关于什么的. 一个强有力的戏剧性前提是大多数成功故事的基础.
故事情节是一条简洁的线,捕捉故事的主要思想、冲突和角色,概述其基础和方向.
如果我们能够自动化设计和创造多样化和高质量的前提,那将是故事生成领域的一大进步。
大多数未来的自动故事生成(ASG)框架都可以从使用这些生成的前提中受益,以全面和彻底地评估他们框架的有效性。
**假设**
我们采用第二种方法,利用LLM的广泛知识来生成众多故事情节,但是专注于诱导细粒度模块。
作为回应,我们引入了模块化故事情节合成(MoPS):
它将完整的前提分解为模块,
收集模块候选者到一个层次结构中,
概述从选定元素中提取的前提设计,
并最终让LLM将这些合成为一个连贯的故事前提句子
MoPS包括三个阶段:
(1)预收集每个模块的一致候选集以形成一个嵌套字典;
(2)从嵌套字典中提取关键路径作为前提设计;
(3)指导大型语言模型(LLM)将设计整合成一个连贯的前提句子。
**MoPS-Overview**
核心思想:将前提设计转化为在每个模块内候选者的抽样,将开放式从头开始的生成转化为模块元素的合成。
1. Anatomy of Story Premise
前提解剖为四个有序模块:主题、背景、人物和情节,每个模块进一步细分为子模块。
- 主题:玄幻、悬疑、都市等
- 背景:细分为时间、地点及其组合,
- 人物:细分为成长、冲突和合作三个类别,
- 情节:细分为事件、结局和转折
2. Dependency between Modules
模块间存在序列依赖关系:主题 --> 背景 --> 人物 --> 情节
- 主题:确定中心思想
- 背景:确定故事发生的时空背景, 为人物和情节模块提供了舞台
- 人物:是前提的核心,通过角色的行为和决策推动情节向前发展
- 情节:是故事发展的主体,
主要事件构成了贯穿叙事的骨干,
结局提供了清晰的解决方案,确保了前提的闭环,
转折可以增强前提的吸引力并使其引人入胜
3. Insight behind Modular Design
MoPS 的有效性主要来自于其模块化设计,体现了组合创造力的概念
**Induce Candidates from LLM**
模块候选者的数据结构。诱导过程本质上形成了一个嵌套字典 D。
第一层是主题字典,每个键是一个主题候选者,每个值是该主题对应的背景字典。
随后,人物、事件、结局和转折字典依次嵌套。
从 D 中抽样一个关键路径作为前提设计。
通过对整个嵌套字典执行前序遍历,我们可以实现模块候选者的广泛组合,显著促进组合创造力,生成独特和创新的故事前提。
**Deduplication for Module Candidates**
对于LLM重复生成的问题,在添加新候选者时,使用余弦相似性进行过滤。
**Resilience for Human-in-the-Loop**
人工遵循相同的方法,介入某个步骤,或逐个想出每个组件;然后利用LLM进行合成。
**Premise Synthesis**
从嵌套字典中抽样一个关键路径作为前提设计,我们指导 LLM 将前提设计融合成一个紧凑、简洁、连贯的句子作为故事情节。参见下图。
**Self-Verification**
增加校验模块:在合成程序之后,我们进一步指导 LLM 自我验证合成的前提是否包含任何明显的不一致性或事实错误(见表 17 中的提示)。如果有,那么这个腐败的前提将被丢弃。
**MoPS-Dataset**
**Complete Version**
候选项:14个主题,30个背景,9个角色(成长、冲突、合作,各3个),2个主要事件(每个事件一个结局,每个结局一个转折)
前序遍历:共获得7600个前提
验证:使用GPT3.5-turbo进行验证,得到7599
**Moderate Version**
随机抽取1000个样本,利用Dramatron和RecurrentGPT生成剧本和小说
**Curated Version**
筛选100个样本,合成的前提可以作为评估后续故事生成方法的基准


RENARGEN
论文:Returning to the Start: Generating Narratives with Related Endpoints
2024.04
1
2
3
4
5
6
7
8
9
10
**问题**
人类作家通常会在文章开头和结尾使用相关的句子来构成一个令人满意的叙事,以"闭合循环"的方式来完成。
**假设**
RENarGen,一种可控的故事生成范式。
试图通过确保故事的第一句和最后一句相关,
然后填充中间句子来生成叙述性故事,
以解决当前自回归模型在故事生成中缺乏叙述性结构的问题。
Do Language Models Enjoy Their Own Stories?
论文:Do Language Models Enjoy Their Own Stories? Prompting Large Language Models for Automatic Story Evaluation
2024.05
自动故事评估 - AutoStoryEval - ASE
1
2
3
4
5
6
7
8
9
10
11
12
13
14
**问题**
LLM是否可以替代人工进行ASE?
**评估维度**
- 相关性(Relevance, RE):故事与其提示(prompt)的匹配程度。
- 连贯性(Coherence, CH):故事的逻辑性和是否易于理解。
- 共鸣(Empathy, EM):读者对故事中角色情感的理解程度。
- 惊喜(Surprise, SU):故事结局的出人意料程度。
- 参与度(Engagement, EG):读者对故事的投入程度。
- 复杂性(Complexity, CX):故事的复杂程度或精巧程度。
**结论**
1. LLMs在系统级评估中与人类评价展现出高相关性,但在个别故事的解释能力上存在不足
2. 可解释性较差
Reading Subtext
论文:Reading Subtext: Evaluating Large Language Models on Short Story Summarization with Writers
2024.03
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
**问题**
与作者合作,使用未发表的短篇小说,评测LLM的短篇小说摘要总结的能力。
**亮点**
展示了如何与领域专家合作,评估LLMs在特定范式上的表现。
**评估维度**
- 覆盖度(Coverage):评估摘要是否覆盖了故事中重要的情节点。
- 忠实度(Faithfulness):评估摘要是否准确代表了故事的细节,或者是否编造了内容。
- 连贯性(Coherence):评估摘要是否连贯、流畅且易于阅读。
- 分析(Analysis):评估摘要是否提供了对故事主要观点或主题的正确分析。
**具体流程**
1. 故事和作者筛选:招募拥有未发表作品的熟练作家。
2. 数据准备:收集作家提交的未发表短篇故事,使用匿名ID保护作家隐私。
3. 摘要生成:使用GPT-4、Claude-2.1和LLama-2-70B生成故事摘要。对于长故事,LLama采用分块总结方法。
4. 评估维度:覆盖度、忠实度、连贯性、分析。
5. 评估实施:跨度级别错误分类、摘要级别评级、故事级别风格分析。
6. 自动与人工评估比较:对比LLM评分和作家评分,评估LLM作为评估者的能力。
**结论**
LLM在总结短篇小说时能够展现出对长篇叙事和主题分析的理解,
在具体性和对潜台词及叙事声音的可靠解读方面存在挑战,
且LLM评级不能替代专业人类评审的评估。
CollabStory
论文:CollabStory:Multi-LLM Collaborative Story Generation and Authorship Analysis
2024.06
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
**问题**
LLMs之间合作进行开放式任务是否可行?达到什么程度?
**研究的目的**
1. 创建CollabStory数据集:生成第一个专门由多个LLMs合作生成的故事数据集,称为CollabStory,以支持对LLM-LLM合作的理解和技术开发。
2. 多作者写作场景:研究从单一作者(N=1)到多作者(多达N=5)场景下的LLM合作写作,即多个LLMs共同创作故事。
3. 评估LLM合作能力:通过生成的CollabStory数据集,评估LLMs在合作写作任务中的表现,以及随着作者数量增加,故事质量的变化。
4. 扩展PAN任务:受到PAN任务的启发,将与作者相关的任务从人与人之间的合作扩展到多LLM设置,为机器-机器合作设置基线,并评估现有技术在这一新场景下的表现。
5. 推动技术发展:通过CollabStory数据集,推动对使用多个LLMs的理解和新技术的发展,以识别文本中多个LLM的使用,这对于研究和实际应用都至关重要。
6. 探索作者归属问题:探讨在多LLM合作生成的文本中,如何确定真正的创意来源,以及如何分配作者信用和所有权。
**评估多LLM合作的故事质量**
1. 数据集分析
比较LLM生成的单作者和多作者文本与人类写作的故事:通过报告不同指标的平均值和标准差来比较LLM生成的故事与人类写作故事的相对质量。这些指标包括:
- 平均单词数
- 句子数
- 词汇丰富度
- 停用词百分比
- 可读性分数
- 熵
- 连贯性分数
2. 故事连贯性评估
使用GPT-4o进行基于提示的评估:评估由不同LLM作者顺序生成的故事部分是否逻辑上和情节上连贯。通过比较"正确"的下一个故事部分(即实际的下一部分)与"不正确"的负样本(即随机选择的故事部分,可能是来自同一故事的其他部分,或来自不同故事的部分)的连贯性评价,来确定故事的连贯性。
3. 作者任务相关的评估
扩展PAN任务:将PAN任务中常见的作者相关任务(如抄袭分析、作者识别和近重复检测)扩展到多LLM场景,并使用以下五种基线方法进行微调和性能报告:
- 多项式朴素贝叶斯(MNB)
- 支持向量机(SVM)
- BERT
- ALBERT
- RoBERTa
4. 具体任务
- 任务1:故事是否由多个作者撰写:通过随机抽样单LLM撰写的故事(N=1)作为负类,与多作者设置(N∈[2,3,4,5])作为正类,来预测故事是否由多个作者撰写。
- 任务2:预测故事的作者数量:预测生成故事涉及的作者数量,标签类别为[1, 5]。
- 任务3:作者验证:预测两个连续句子是否由同一作者撰写。使用LLM-LLM边界的所有句子对,即部分i的最后一句话和部分i+1的第一句话。
- 任务4:作者归属:预测文本的确切作者。在多LLM文本的情况下,每个数据样本是同质的,每个部分由单一作者撰写,分类器的任务是识别其作者。
Reflections & Resonance
论文:Reflections & Resonance: Two-Agent Partnership for Advancing LLM-based Story Annotation
2024.06
1
2
3
4
5
6
7
我们提出了一个双代理系统,灵感来自AutoGen框架(Wu等人,2023年).
旨在通过协作增强提示的有效性。
- 代理A基于深入的叙事理解开始注释,提出基于提示。
- 代理B随后通过故事重建的视角评估这些提示,并提供反馈,以根据重建故事的准确性来优化提示。
这一过程促进了动态的、迭代的优化,确保提示为最佳故事注释进行了微调

CMDAG
论文:CMDAG: A Chinese Metaphor Dataset with Annotated Grounds as CoT for Boosting Metaphor Generation
2024.02
1
2
3
4
5
6
7
8
9
**Idea**
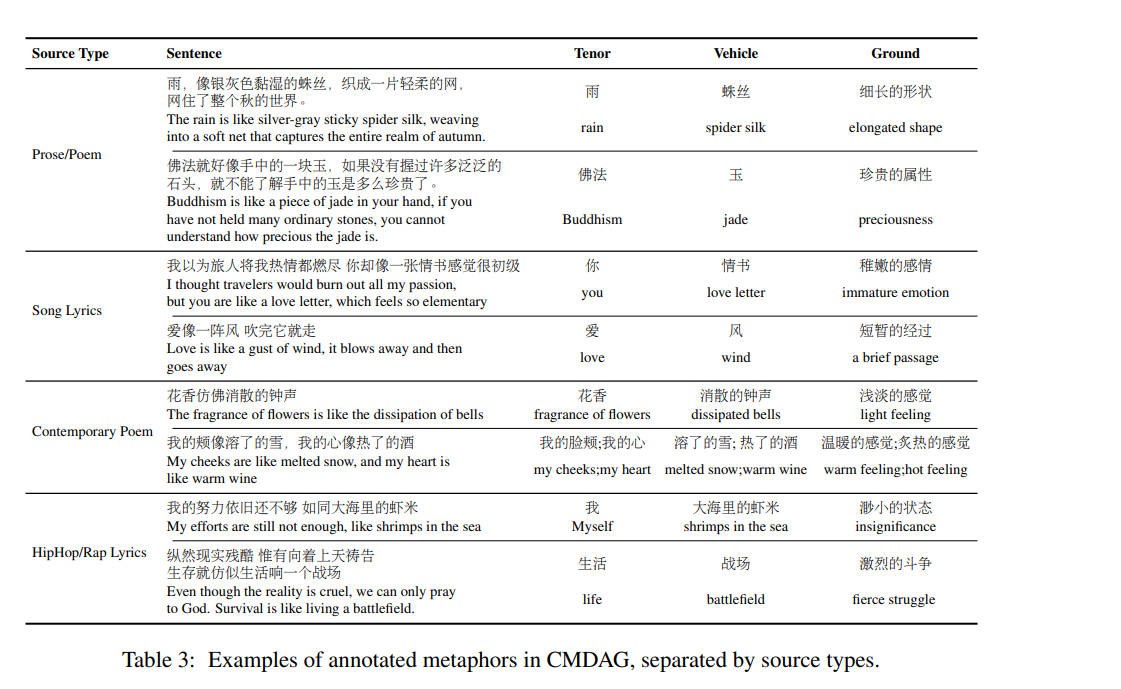
隐喻是人类语言和文学中突出的语言工具,它们增加了色彩、意象和强调,以增强有效沟通。
构建了一个大规模、高质量的标注了基础(CoT)的中文隐喻语料库,该语料库包含约28K个句子,这些句子来自多种中文文学来源,如诗歌、散文、歌词等。
**主要贡献**
1. 我们提出了CMDAG,一个独特的中文隐喻数据集,其关键特点是包含了基础。这个数据集的精心设计使隐喻结构的直观生成成为可能,解决了当代研究文献中的一个显著空白。
2. 我们引入了一个隐喻标注流程,利用学术专业标注者的专业知识,提高了确定隐喻基础的精度。
3. 我们提出了第一个将CoT引入隐喻生成的工作。给定本体和喻体,使用CoT推导基础,语言模型可以生成连贯和综合的隐喻句子。
Analyzing Nobel Prize Literature
论文:Analyzing Nobel Prize Literature with Large Language Models
2024.10
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
**IDEA**
对比最先进LLM与研究生在文学分析上的表现。
诺贝尔奖获奖短篇小说:韩江的《九章》(2024年获奖者)和乔恩·福斯的《友谊》(2023年获奖者)
研究探索了人工智能在涉及复杂文学元素方面的参与程度,如主题分析、互文性、文化和历史背景、语言和结构创新以及角色发展。
使用了O1模型
**结论**
1. LLMs作为有能力的文学分析师,定量和定性评估表明,o1模型在几个维度上与人类参与者表现相当,特别是在创造力和对文本的忠实度方面。
2. LLMs可以提供客观的、基于文本的解释,可能补充或增强人类专家,特别是在需要细致内容遵循的任务中。
3. LLMs在连贯性和情感细微差别方面表现出明显的不足。
尽管像o1模型这样的LLMs能够执行严格的文本分析,但它们最适合于客观准确性和创造力优先于情感和审美解释的角色
**评估维度及Prompt**
- 主题分析(Thematic Analysis):
确定作品的中心主题,并讨论它们在叙事更广泛背景下的重要性。
- 互文性和文学影响(Intertextuality and Literary Influence):
检测并评论任何来自其他文学传统或作品的引用或影响,这些引用或影响塑造了叙事的含义。
- 文化和历史背景(Cultural and Historical Contexts):
分析故事如何反映或批评其被撰写时的文化和历史时期,并提供对社会含义的见解。
- 语言和结构创新(Linguistic and Structural Innovations):
突出任何语言或叙事结构的创新使用,例如非线性叙事或意识流等风格技巧。
- 角色发展(Character Development):
检查中心角色的发展,重点关注他们的动机、内在冲突和心理深度。
- 道德和哲学洞察(Moral and Philosophical Insights):
讨论文本中存在的任何道德困境或哲学主题,以及这些如何有助于其更深层的含义。
- 叙事技巧和时间结构(Narrative Techniques and Temporal Structure):
探索叙事风格、节奏、使用时间以及任何视角的转变,这些影响读者的体验。
- 情感基调和心理深度(Emotional Tone and Psychological Depth):
调查文本的情感氛围,特别是它如何通过角色的描绘传达心理复杂性。
Evaluating Character Understanding
论文:Evaluating Character Understanding of Large Language Models via Character Profiling from Fictional Works
2024.04
role-playing agents (RPAs) - 角色扮演代理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
**问题**
角色扮演代理(RPAs)非常受欢迎,尤其是针对虚构角色的应用。
这些RPAs的先决条件在于LLMs理解虚构作品中角色的能力。
角色画像确实是通过生成来探索LLMs角色理解深度的第一个任务。
有助于更细致地理解LLMs如何理解角色。
挑战主要包括缺乏高质量数据集和评估协议。
**用户画像的维度**
- 属性:角色的基本属性包括性别、技能、才能、目标和背景。
- 关系:角色的人际关系是他们画像的一个重要方面,与角色的经历和个性密切相关。此外,这些关系可以作为构建虚构角色关系图的基础。
- 事件:事件涵盖了角色参与或受影响的经历,标志着一个关键的画像维度。由于某些叙事的复杂性,例如交替的时间线和展示来自不同世界或不同视角的事件,我们要求模型重新排列事件并按时间顺序排列它们。
- 个性:个性指的是形成个体适应生活的独特方式的持久特征和行为集合(美国心理学会,2018)。虽然全面的角色经常表现出复杂的个性,但他们的个性可以通过他们的行动、选择和与他人的互动来分析。
LONGWRITER
论文:LONGWRITER: UNLEASHING 10,000+ WORD GENERATION FROM LONG CONTEXT LLMS
2024.08
https://zhuanlan.zhihu.com/p/864482453
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
**问题**
大模型的上下文(Context)支持越来越长的背景下,让LLM遵循指令来保障长文本输出的长度,依然是一个挑战。
希望针对超长输出(10000+ words)场景,训练一个能胜任该任务的模型
**假设**
对于GPT-4o、LLama3.1-70B、Claude3.5试验,即使指定了输出10000字的文章,但通常无法超过2000字
原因在于:模型所能生成的最大长度,会受限于其SFT数据中存在的输出长度上限。
以智谱的GLM4-9B-Chat模型为例,
其SFT训练使用的180K条chat数据中,
输出长度超过500、1,000和2,000字的数据,分别仅占SFT数据量大的28%、2%和0.1%。
假设:构建长输出的训练数据集,可以提升模型的长文本输出能力
**数据剔除**
在LongWriter-6k数据基础上,实施了两个数据清洗剔除策略:
1. 剔除prompt中对输出长度没有明确要求(Required Length)的数据
数据总量:6000条 --> 1748条
2. 剔除输出长度和prompt中的Required Length差距较大的数据,即eval_length score--SL得分小于80分的数据
数据总量:1748条 --> 666条
**训练方法**
- 监督微调 - SFT
Model:GLM-4-9B和Llama-3.1-8B。
Context:最大128k令牌的上下文窗口,使其天然适合长文本输出训练。
GPU:8xH800 80G, DeepSpeed+ZeRO3+CPU
Batch Size:8
Learning Rate:1e-5
Pack Length:32k
Epoch:4
- 对齐(DPO)
Model:LongWriter-9B
Data: 50K
Sampling: 得分最高的输出作为正样本,剩余三个输出中随机选择一个作为负样本
**结论**
1. 少即是多:数据质量比数据数量更关键。
我们从中选出了10%左右(666条)的高质量数据并基于这些数据做微调训练。在Qwen2-7b-instruct和GLM4-9B-Chat两个模型上,只需要3.7%训练计算消耗,就能获取了和原论文中,LongWriter-GLM-9B类似的性能提升。
2. 对于提升输出文本长度这个具体任务,从base模型开始SFT似乎不是必须的。
以对齐版本(chat/instruct)模型为起点,在模型输出质量和输出长度两方面,也都能获取较好的效果。
3. 基础模型在不断迭代,支持长输出的这个能力也会逐渐集成到新的模型中。
比如最近Qwen系列刚刚推出的Qwen2.5,对于生成长度的支持就有了长足的提升。我们也第一时间做了初步的测试和验证。

WHAT-IF
论文:WHAT-IF: Exploring Branching Narratives by Meta-Prompting Large Language Models
2024.12
interactive fiction (IF) - 互动小说
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
**背景**
互动小说(IF)是一种基于文本的故事形式,用户执行某些动作来推动情节发展。从"选择你自己的冒险"书籍到开放世界视频游戏,分支叙事是互动小说中一个有趣的元素,它使读者能够改变叙事的结果。
**假设**
从人类编写的情节开始,
WHAT-IF通过考虑主角可能采取的替代行动来产生情节的显著变化。
我们通过让大型语言模型(LLM)为角色生成一个新的子目标来创建这些选择点,
这将显著改变故事中随后的情节点。
并且允许用户选择故事树中跟随哪些分支;
WHAT-IF生成的故事更为受限,用户有一定的控制权,
但由LLM生成的故事与原始故事保持高度的主题一致性,即使有许多可能的结局。
**结构可以帮助LLM更好地理解故事**
WHAT-IF将叙事分解为事件,以便在整个生成过程中跟踪情节的结构。
在用户玩游戏之前生成的分支情节结构,每个故事分支都将导致一个结局。
由于每个故事需要提出不同的问题来生成假设性的替代情节,我们还采用了元提示。
也就是说,系统生成特定于故事的提示,然后输入到另一个LLM实例中以获得答案。
尽管我们将系统呈现为一个互动小说游戏,但我们相信WHAT-IF也可以用来帮助作者探索他们正在编写的故事线中的替代路径。
**系统架构**
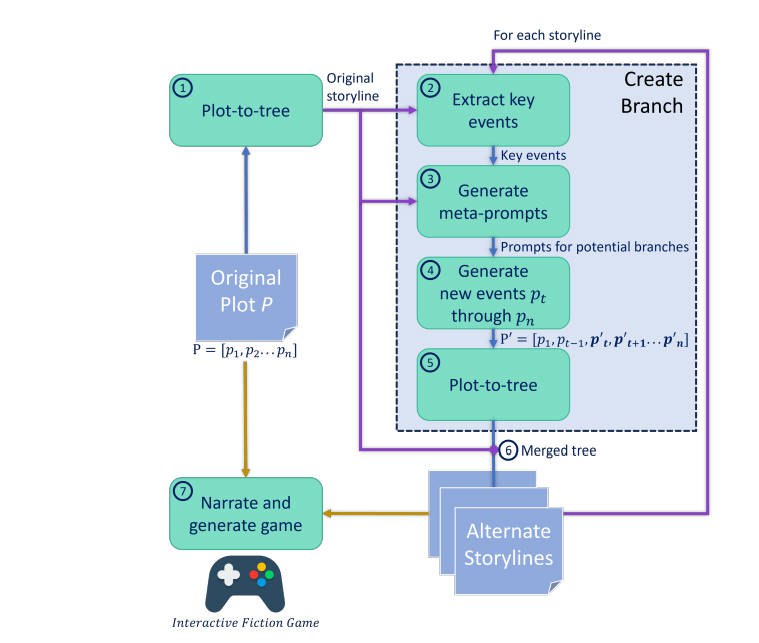
WHAT-IF由五个主要阶段组成:
1. 初始化分支情节树
我们创建了一个分支情节树结构来捕捉给定故事情节中的关键决策作为分支点。在这里,我们定义一个关键决策为主角色在对给定状态(障碍、危险等)的响应中所做的决策。
2. 提取关键事件
GPT-4倾向于想象出要么与原始故事偏离太多,要么陷入具体细节导致故事停滞的故事。
一个有效的解决方案是提供故事结构。
一个著名的故事结构是三幕结构,它将故事分为三个阶段:设置、对抗和解决。
这个结构的骨干是三个主要情节点:激励事件、危机和高潮。这些主要情节点迫使主角经历和成长,并推动紧张情绪上升和下降,导致引人入胜的故事。
因此,我们提示GPT-4从情节线的所有边事件中识别出对应这三个主要情节点的三个关键事件,并将其保存以备后续在提示生成中使用。
3. 生成元提示
尽管理想的故事应该展示而不是告诉,我们观察到LLM倾向于过于直接地遵循指令。例如,"替代故事情节应该包含新挑战..."的提示会导致事件如"Tony面临一个新的挑战..."。
因此,我们采用了元提示方法(即提示生成提示),这已被证明是一种有效的方法,可以从LLMs中引出更好的响应。
具体来说,我们要求GPT-4为每个节点生成一个提示,提供:
(1)如果主角在事件et做出决策AD而不是KD,那么在et事件处分叉的替代故事情节;
(2)5个具体的指导问题,扩展:
(2a)AD如何改变和替换关键事件,
(2b)主角如何做出关键决策,克服新挑战并推动故事向前发展;
(3)一个理想的替代故事情节
(4)严格遵守原始故事情节中给定的事件;
(5)作为以AD为第一个事件的事件列表输出。
通过遵循原始故事情节中的关键事件作为上下文的具体指导问题,GPT-4能够生成保持三幕故事结构的连贯故事,确保稳定的叙事节奏和角色发展。
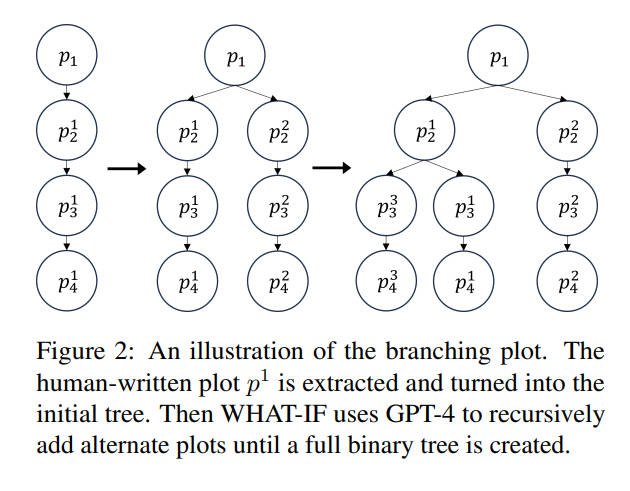
4. 分支和合并树
有了为原始故事情节的每个节点生成的元提示,系统递归地在每个节点分叉,并相应地写出替代故事情节:
1. 从原始故事情节图的所有边提取事件,并将它们包含在相应节点的提示中。
2. 生成从先前(提取的)事件开始的新事件列表。(见图3的#4)
3. 根据新事件列表创建一个分支。(见图3的#5)
4. 将先前事件(旧情节树)和新事件的分支合并,形成一个新的分支情节树。(见图3的#6)
5. 从新情节线中提取关键事件。
6. 使用第3.3节中的程序为分支上的所有节点生成提示。
7. 递归地在分支的所有节点上分叉,并写出替代故事情节。当所有元提示都使用完毕后返回。
5. 叙述游戏
在我们完成二叉分支情节树之后,我们的游戏中有2^n个可能的故事结局,其中n是原始故事情节中的节点/事件数量。WHAT-IF通过提示GPT4叙述每个节点nt的所有事件Et−1来遍历树,这些事件Et−1指向从前一时间步骤的节点。之后,它会叙述角色的状态St和目标Gt。
**效果**
Show, Don’t Tell - LIIPA
论文:Show, Don’t Tell: Uncovering Implicit Character Portrayal using LLMs
2024.12
编剧界最著名的格言一共有三句:
“write what you know” ——写你了解的东西。
“writing is rewriting”——写作就是不断重写的过程。
“show, don’t tell.”——展示,而不是告诉。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
**问题**
人物塑造是文学中的重点。现有的人物分析通常集中在显性特征上,对于隐性特征很难分析和评判。
**主要贡献**
1. 引入了ImPortPrompts(隐性描绘提示),这是一个用于隐性人物描绘分析的数据集
2. 提出了LIIPA框架,用于分析和评估隐性人物描绘
3. LIIPA的不同配置(结构化输出、提示类型)实现了公平性-准确性权衡
- (LIIPA-direct最大化准确性,LIIPA-sentence最小化不公平性)
- LIIPA-sentence和LIIPA-story在准确性和公平性方面都优于之前的COMET基线。
**LIIPA**
LIIPA (LLMs for Inferring Implicit Portrayal for Character Analysis) 的流程有三种主要变体:
1. LIIPA-sentence(基于句子的分析):
- 输入:将故事拆分成单个句子
- 步骤:对每个句子,让LLM生成描述特定人物的5个属性词列表
- 输出:通过另一个LLM评估程序将这些词列表映射为IAP(智力、外表、权力)标签
2. LIIPA-story(基于整个故事的分析):
- 输入:使用完整的故事文本
- 步骤:让LLM基于整个故事上下文为每个人物生成5个属性词列表
- 输出:同样通过LLM评估程序将词列表映射为IAP标签
3. LIIPA-direct(直接分析):
- 输入:完整的故事文本
- 步骤:直接让LLM根据故事内容评估每个人物的IAP特征
- 输出:直接得到IAP标签,不需要中间的词列表生成步骤
主要特点:
- 使用不同的LLM家族来避免自偏好偏差
- 使用GPT/Claude生成故事
- 使用Gemini进行人物特征分析
- 使用GPT-4作为评判器
性能比较:
- 准确性排序:LIIPA-direct > LIIPA-story > LIIPA-sentence
- 公平性排序:LIIPA-sentence > LIIPA-story > LIIPA-direct
- 存在准确性和公平性的权衡
优势:
- 可以处理更长的文本和更多的人物
- 能够利用完整的故事上下文
- 比传统方法(如COMET)表现更好
这三种变体为不同的应用场景提供了灵活的选择,用户可以根据需要在准确性和公平性之间进行权衡。
**ImPortPrompts数据集:
ImPortPrompts数据集是专门为隐含人物特征分析任务设计的数据集,其主要特点如下:
1. 数据集设计目标:
- 提供更好的跨主题相似性
- 更高的词汇多样性
- 更广泛的人物角色表现
- 专注于隐含而非显式的人物特征描写
2. 数据集规模与结构:
- 包含2000个样本(故事)
- 每个故事包含1-5个人物
- 故事长度在5-30句之间
- 为每个人物标注三个维度(智力、外表、权力)的特征
3. 主要约束条件:
- 人物角色约束:每个故事必须包含指定数量的角色(主角、反派、受害者)
- 隐含描写约束:避免直接使用描述性词汇(如"聪明的"、"漂亮的"等)
- 社会人口学约束:避免提及性别、种族、宗教等人口统计信息
- 格式约束:使用特定的命名方式(如Protagonist1、Antagonist1等)
4. 相比现有数据集的优势:
- 比TinyStories和ROCStories有更好的词汇多样性
- 比WritingPrompts有更稳定的故事长度分布
- 更平衡的角色分布(不同于其他数据集过度关注主角)
- 更好的跨主题语义相似性
5. 数据生成方法:
- 使用LLMs(GPT和Claude)生成故事
- 采用树思维(Tree-of-Thoughts)提示策略
- 包含自动和人工验证步骤
6. 质量控制:
- 自动验证:检查字数、角色数量等形式约束
- 人工验证:确保故事符合隐含描写要求
- 过滤不符合要求的样本
7. 评估指标:
- 词汇多样性指标:HD-D、Maas、MTLD
- 语义多样性指标:主题内和主题间相似度、N-gram频率
这个数据集的主要创新在于:
1. 专注于隐含特征描写
2. 提供更均衡的角色分布
3. 确保无人口统计偏见
4. 保持跨主题的一致性
这些特点使得ImPortPrompts成为测试和开发人物特征分析模型的理想数据集。
LFED
论文:LFED: A Literary Fiction Evaluation Dataset for Large Language Models
2024.05
LFED, a Literary Fiction Evaluation Dataset
首个针对评估大语言模型长篇文学小说理解能力的中文数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
**评估维度**
- 角色关系 (Character relationships)
- 人物性格刻画 (Characterization)
- 文学风格 (Literary style)
- 角色行为 (Role behavior)
- 事件关系 (Event relation)
- 小说情节 (Fiction plot)
- 背景主题 (Background topic)
- 反事实推理 (Counterfactual reasoning)
**评估方法**
多项选择题
Modeling Story Expectations
论文:Modeling Story Expectations to Understand Engagement: A Generative Framework Using LLMs
2024.12
在Wattpad上超过30,000本书章节上进行评估
1
2
3
4
5
6
7
8
9
**问题**
理解参与的潜在驱动因素可以帮助内容创作者决定生产什么。
**结论**
一个使用大型语言模型来模拟故事中观众期望的框架。
我们的方法将叙事内容转化为代表观众期望、不确定性和惊喜的特征,为理解用户参与提供了见解。
我们的核心方法论是一个将叙事内容转化为特征的过程,这些特征代表了观众的期望、不确定性和惊喜。
为了证明其有效性,我们将我们的方法应用于Wattpad上的超过30,000本书章节。
Dynamic Hierarchical Outlining
论文:Generating Long-form Story Using Dynamic Hierarchical Outlining with Memory-Enhancement
2024.12
DOME:Dynamic Hierarchical Outlining with Memory-Enhancement long-form story generation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
**问题定义**
1. 对于作家给定的StoryPremise(I), 以及写作理论框架WriteTheory(WT)
2. 我们设计了一个Framework(F*)来生成a long-form story(S)
3. 故事S在情节连贯性上的得分是C^Plot,故事S在上下文连贯性上的得分是C^Context。
4. 我们的目标是生成一个故事S,以提高C^Plot和C^Context。
**问题**
现有的长篇故事生成方法基于计划-写作框架分离了规划和写作阶段,这使得它们无法适应写作阶段的不确定性。
此外,通过这种两阶段方法生成的故事往往在开始时就突然停止,导致情节缺失。
另一种方法包括人类参与的详细大纲偏好,提高了大纲的灵活性,但使得整体故事线无法控制或不完整。一个直观的想法出现了:如果我们能进一步从情节流畅性和完整性方面提高故事连贯性,会怎样?
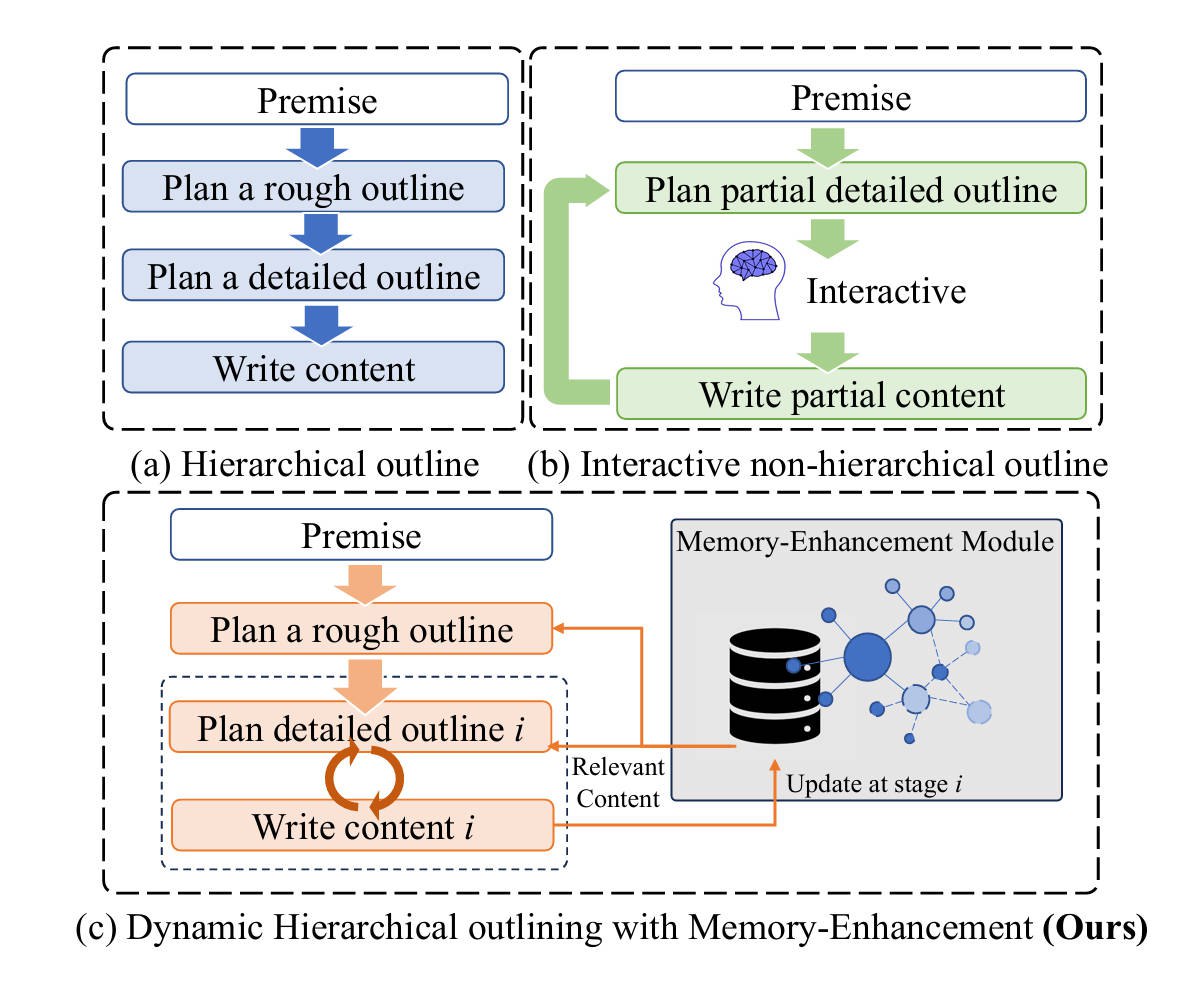
**Motivation**
我们基于Yang等人(2023)提出的分层大纲概念,结合小说写作理论和知识图谱(Pan等人,2024),设计了一个动态大纲生成系统。
1. 系统首先生成粗略大纲,确保包含所有故事阶段,然后逐步扩展为详细大纲,以适应生成不确定性。
2. 为解决上下文不一致性问题,我们引入了记忆模块和LLM过滤器,提供简洁的相关内容,提高上下文一致性。
**方法**
1. DHO - 动态分层规划
- 分为粗略大纲(Rough Outline)和详细大纲(Detailed Outline)两个层次
- 粗略大纲基于小说写作理论(Campbell的五阶段理论)生成,确保故事情节完整性
- 详细大纲根据粗略大纲和MEM提供的相关内容动态生成,每个粗略大纲会扩展生成3个详细大纲
- 故事内容基于详细大纲和MEM提供的相关历史内容生成
2. MEM - 基于时序知识图谱的记忆增强模块
- 使用时序知识图谱(TKG)存储生成的故事内容
- TKG以四元组形式<主语,动作,宾语,索引>存储信息
- 通过基于实体的检索和LLM语义过滤提供相关历史内容
- 过滤规则基于语义相关性,返回top-k个最相关内容
3. 时间冲突分析器
- 一种基于时间知识图谱信息表示规则的潜在冲突检测方法,
- 并应用LLM进一步确定是否存在冲突
- 实验表明,这种方法的判断结果与人类偏好一致。
**流程**
1. 生成粗略大纲(Rough Outline)
- 输入包括:用户输入I(包含故事设定、人物介绍等)、小说写作理论WT(Campbell的五阶段理论)、粗略大纲生成提示词Prough_outline
- 使用公式:R = LLM(WT, I, Prough_outline)
- 目的是确保故事包含完整的五个阶段(开端、上升、高潮、下降、结局)
2. 生成详细大纲(Detailed Outline)
- 详细大纲D = {di}5i=1,对应五个阶段
- 每个阶段的详细大纲基于:
- 对应的粗略大纲部分ri
- MEM模块提供的相关历史内容RInfo.i
- 详细大纲生成提示词Pdetailed_outline
- 使用公式:di = LLM(ri, RInfo.i, Pdetailed_outline)
- 每个粗略大纲ri会扩展生成M个详细大纲(文中M=3)
3. 基于详细大纲生成故事内容
- 对每个详细大纲doti:
- 从MEM获取相关历史内容DInfo.ti
- 使用公式:sti = LLM(doti, DInfo.ti, Pgen_story)生成部分故事内容
- 将生成的内容存入MEM的时序知识图谱中
4. DOME还提出了一个时序冲突分析器,用于自动评估故事的上下文一致性:
- 基于TKG中的四元组检测潜在冲突
- 使用LLM进一步判断是否存在实际冲突
- 通过计算冲突四元组占比来衡量一致性
How good is my story?
论文:How good is my story? Towards quantitative metrics for evaluating LLM-generated XAI narratives
2024.12
关于描将定量解释(如SHAP)转换为用户友好的叙述,跟小说无关
Dramatron
论文:Co-Writing Screenplays and Theatre Scripts with Language Models: Evaluation by Industry Professionals
2022.04
Dramatron 是一个所谓的「联合写作」工具
你给它一句话(log line)描述中心戏剧冲突(比如 James 在有 Sam 鬼魂出没的后院发现了一口井), 它就能自动写出标题、角色、场景描述和对话。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
**问题**
LLM是否可以创作剧本?
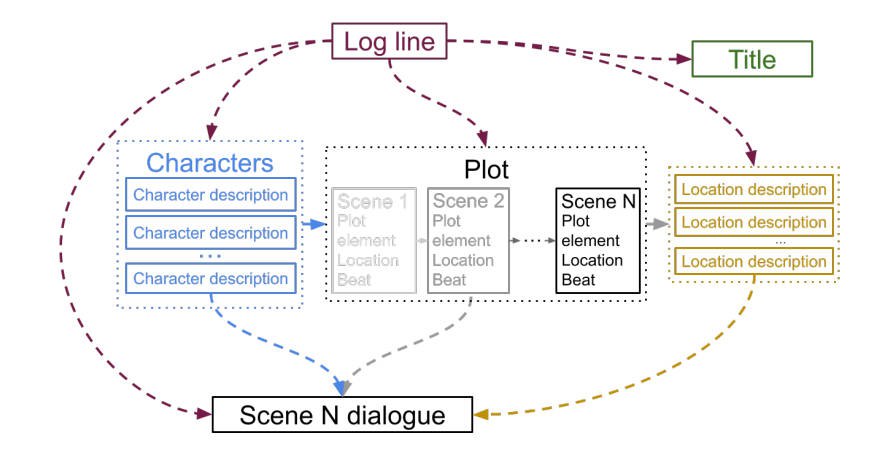
**什么是Dramatron?**
BaseModel:LLM,such as GPT-4, Claude, Gemini, etc.
Major Method:
- 分层故事生成( hierarchical story generation)
- 精心设计的 prompt
- 具有结构化生成能力的 prompt chaining
Advantage:
- 整个脚本的长程一致性
- 比「扁平的」序列文本生成更具有故事连贯性
**Dramatron 工作流程**
1. **输入阶段**
- 用户提供一句话的核心戏剧冲突描述(log line)
- 这个 log line 作为整个生成过程的种子输入
2. **分层生成阶段**(按顺序)
按层次生成内容:从故事梗概→标题→人物→情节大纲→场景描述→对话
- 标题(Title)生成
- 角色(Characters)生成
* 角色描述列表
* 每个角色的详细特征
- 情节(Plot)生成
* 场景序列摘要
* 每个场景的设置和节奏
- 位置(Location)生成
* 每个场景的具体位置描述
- 对话(Dialogue)生成
* 基于前述所有元素
* 为每个场景生成具体对话内容
3. **交互特性**
- 用户可在任何生成阶段进行干预
- 支持人机协作编剧
- 保持整体剧本的长程一致性
4. **技术特点**
- 适用于任何支持 prompt 输入的 LLM
- 使用 prompt chaining 技术
- 采用分层结构确保故事连贯性
**叙事结构1 - 弗赖塔格金字塔结构(Freytag's Pyramid)**
1. 开端/引子(Exposition)
- 介绍背景、人物和基本设定
- 建立故事的基调和氛围
2. 引发事件(Inciting Incident)
- 打破平衡的关键事件
- 推动主角进入故事主线
3. 上升动作(Rising Action)
- 由一系列递进的事件组成:
- 冲突(Conflict)
- 复杂化(Complication)
- 困境(Dilemma)
- 情节张力逐步升级
- 推动故事向高潮发展
4. 高潮(Climax)
- 故事的转折点
- 冲突达到最高点
- 主角面临最大挑战
5. 下降动作(Falling Action)
- 高潮后的余波
- 解开各种悬念
- 情节逐渐平缓
6. 结局(Resolution/Denouement)
- 所有冲突得到解决
- 故事达到新的平衡
- 给读者一个完整的交代
这个结构提供了一个清晰的叙事框架,帮助作者构建张力递进、高潮明确的故事。它特别适用于戏剧性较强的作品,如小说、电影和戏剧等。
**叙事结构2 - 英雄之旅**
英雄之旅的主要阶段
1. 平凡世界 (Ordinary World)
- 展示英雄的日常生活
- 建立对比以凸显后续冒险的非凡性
2. 冒险召唤 (Call to Adventure)
- 打破平衡的事件
- 英雄面临选择或挑战
3. 拒绝召唤 (Refusal of the Call)
- 英雄最初的犹豫或抗拒
- 突显任务的艰巨性
4. 遇见导师 (Meeting with the Mentor)
- 获得指引和帮助
- 获得必要的工具或建议
5. 跨越第一道门槛 (Crossing the First Threshold)
- 正式踏上冒险之路
- 离开熟悉的环境
6. 考验、盟友与敌人 (Tests, Allies and Enemies)
- 经历各种挑战
- 结识朋友和对手
- 学习新的技能
7. 接近最深洞穴 (Approach to the Inmost Cave)
- 准备面对最大挑战
- 到达危险的核心地带
8. 严峻考验 (Ordeal)
- 面对最大的危机
- 经历象征性的死亡与重生
9. 获得奖励 (Reward)
- 战胜考验后的收获
- 获得特殊物品或能力
10. 归途 (Road Back)
- 开始返回之旅
- 面对归途中的挑战
11. 复活 (Resurrection)
- 最后的考验
- 完成最终蜕变
12. 带着灵药回归 (Return with the Elixir)
- 回到原点
- 带来改变或救赎
- 分享冒险的成果
特点与应用
- 循环结构:故事最终回到起点,但主角已经发生改变
- 普遍性:适用于各种文化背景的故事
- 灵活性:不必严格遵循所有步骤,可以根据需要调整
- 深层意义:反映人类共同的心理成长历程
这个框架被广泛应用于电影、小说、游戏等叙事作品中,因为它反映了人类普遍的成长和蜕变过程。
**核心Prompt模版**
Dramatron共使用了5类核心Prompt模板,每个都有特定的功能:
1. Title Prompt(标题提示)
- 输入:log line(故事梗概)
- 输出:故事标题
- 包含示例:如《美狄亚》、《星球大战》等
- 格式要求:简洁且具描述性的标题
2. Character Description Prompt(角色描述提示)
- 输入:log line
- 输出:角色列表及其描述
- 格式:<character>名字<description>描述<stop>
- 包含主要角色特征、关系和动机
3. Plot Outline Prompt(情节大纲提示)
- 输入:log line + 角色描述
- 输出:场景序列
- 每个场景包含:
- 地点(Place)
- 情节元素(Plot element)
- 情节概要(Beat)
- 遵循特定叙事结构(弗莱塔格金字塔或英雄旅程)
4. Location Description Prompt(场景描述提示)
- 输入:log line + 地点名称
- 输出:详细的场景描述
- 目的:为对话提供环境背景
5. Scene Dialogue Prompt(对话提示)
- 输入:多个元素组合
- log line
- 情节元素
- 当前场景概要(Beat)
- 上一场景概要(Previous_Beat)
- 地点名称和描述
- 相关角色描述
- 输出:场景对话
- 格式:标准剧本对话格式
Prompt特点:
- 每个Prompt都有few-shot示例
- 使用特定标记(<end>, <stop>等)
- 支持prompt chaining
- 可根据不同叙事结构选择不同prompt set
Meta-Prompting
论文:Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding
2024.01
Fresh eyes 增加Python解释器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
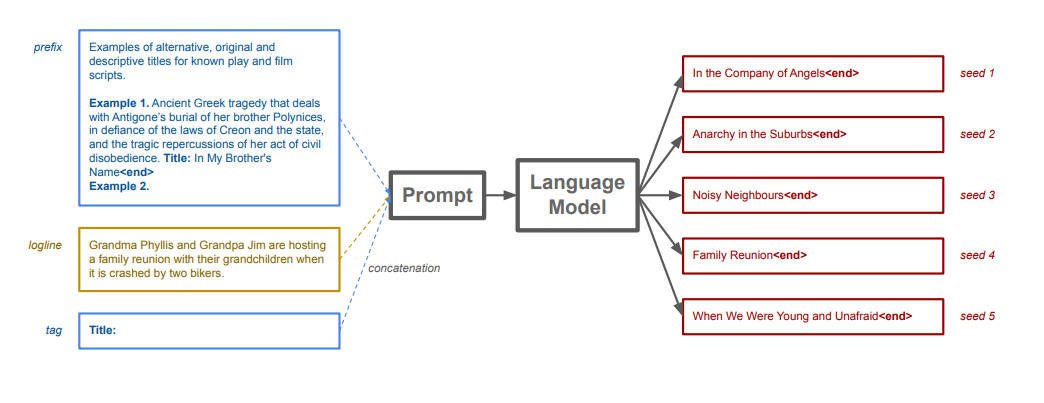
**问题**
尽管这些模型可以解决多种多样的问题,但它们并非总是正确的,有时候也会生成不准确、误导性或矛盾的响应结果。
这些模型的运行成本越来越低,
人们自然会问:
- 是否可以使用脚手架系统(scaffolding system)并使用多个语言模型查询来提升这些模型输出的准确度和稳健性。
**方法**
论文提出了一种称为meta-prompting的技术,这是一种利用模型自身能力的分解和整合技术。
具体步骤包括:
1. 任务分解:主模型将复杂任务分解为更小、更易处理的子任务。
2. 专家分配:每个子任务都交给"专家"模型处理,所谓的"专家"模型是指通过特定指令定制的同一个模型的不同版本。
3. 结果整合:主模型(担任指挥者的角色)将这些"专家"模型的输出结果整合,确保最终结果的一致性和准确性。
4. 结果验证:模型还会进行批判性思考和验证过程,以优化和验证最终输出。
**思想**
- 这种方法能让单个黑箱语言模型既有效作为中心指挥员,同时又充当一系列不同专家,这样便可以得到更加准确、可靠和连贯一致的响应。
- meta-prompting 技术组合并扩展了近期研究提出的多种不同的 prompting 思想,包括高层级规划和决策、动态人设分配、多智能体辩论、自我调试和自我反思。
- 不受具体任务影响
这种 prompting 结构类似于管弦乐队,其中指挥家的角色就由元模型充当,每位音乐演奏者都对应一个不同的特定领域的模型。正如指挥家可以让多种乐器协调弹奏出和谐的旋律一样,元模型也可以将多个模型的解答和见解组合起来,为复杂的问题或任务给出准确且全面的解答。
**Meta-Prompting 与多人设Prompting的差异**
Fresh Eyes 是 meta-prompting 与多人设 prompting 的一大关键差异。
Fresh Eyes 也就是用另一双眼睛看,这有助于缓解语言模型的一个众所周知的问题:犯错时会一路错到底并且会表现出过度自信。
Fresh eyes(新鲜的视角)是Meta-prompting的一个重要特征,具体含义如下:
**基本概念**
每个专家模型在被调用时,只能看到Meta Model提供给它的特定信息
不能看到之前其他专家的完整对话历史
这就像一个全新的视角来看待问题
**主要优势**
- 避免锚定偏见:不会被之前的解决方案所限制
- 减少确认偏误:不会简单确认之前的答案
- 防止过度自信:可以发现之前被忽视的错误
- 提供创新思路:带来全新的问题解决角度
**实际应用举例**
论文提供了一个24点游戏的例子来说明Fresh eyes的作用:
- Meta Model先咨询数学专家提供解决方案
- 第二个专家检查并发现错误
- Meta Model请求编程专家编写验证程序
- 另一个编程专家发现并修正代码错误
- 最后由数学专家验证最终答案
**与其他方法的区别**
- 多人设Prompting中,所有参与者能看到完整历史
- Multipersona prompting中,不同角色共享对话历史
- 只有Meta-prompting采用Fresh eyes机制,确保每个专家提供独立观点
**解决的问题**
- 解决了大语言模型容易"坚持错误"的问题
- 减少了模型过度自信的倾向
- 提高了问题解决的准确性和可靠性
总的来说,Fresh eyes机制通过限制信息访问,确保每个专家能够提供真正独立的观点,这有助于发现错误并产生更好的解决方案。这是Meta-prompting框架的一个重要创新点。
**效果**
meta-prompting 不仅能提升整体性能,而且在多个不同任务上也往往能实现新的最佳结果。
其灵活性尤其值得称道:指挥员模型有能力调用专家模型(基本上就是其本身,只是指令不一样)执行多种不同的功能。
这些功能可能包括点评之前的输出、为特定任务选取特定 AI 人设、优化生成的内容、确保最终输出在实质和形式上都满足所需标准。
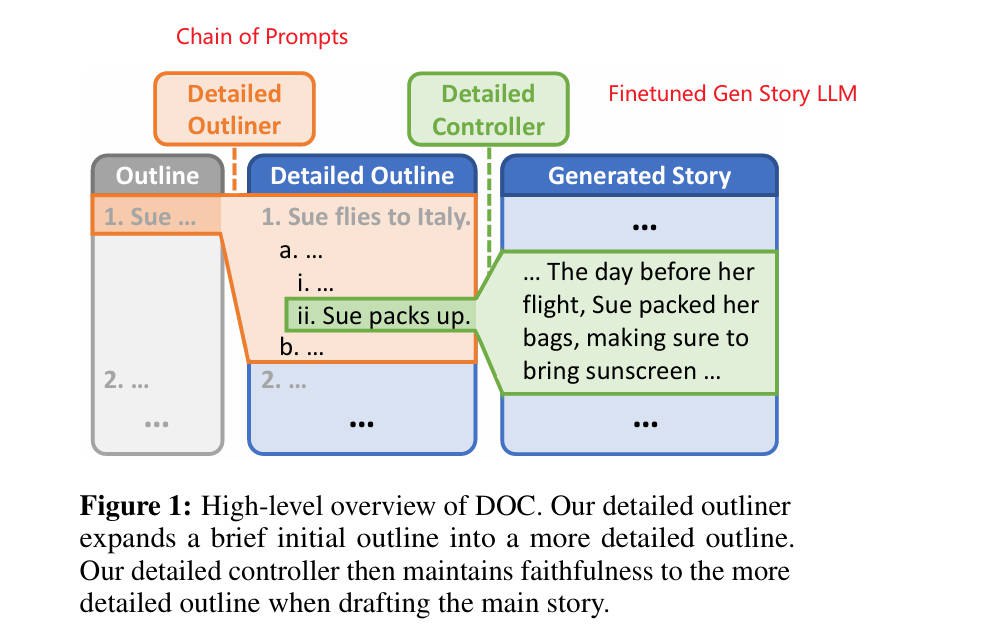
DOC
论文:Doc: Improving long story coherence with detailed outline control.
2022.12
DOC: Detailed Outline Control, 详细大纲控制

Template
论文:Paper-Title
2024.02
1
2
3
4
5
6
7
8
9
**问题**
**方法**
**效果**