Phi-4 Technical Report
精读Phi-4技术报告
Intro
Intro
论文:Phi-4 Technical Report
Phi 来自于希腊字母φ(Phi), 在数学和科学中常用来表示黄金分割比例(Golden Ratio),这个比例被认为是美学和和谐的象征。
Phi系列模型追求的是一种在小型模型中实现高性能的理想比例或平衡!
即在较小的模型规模下达到与大型模型相媲美的性能,体现了“小而精”的目标。
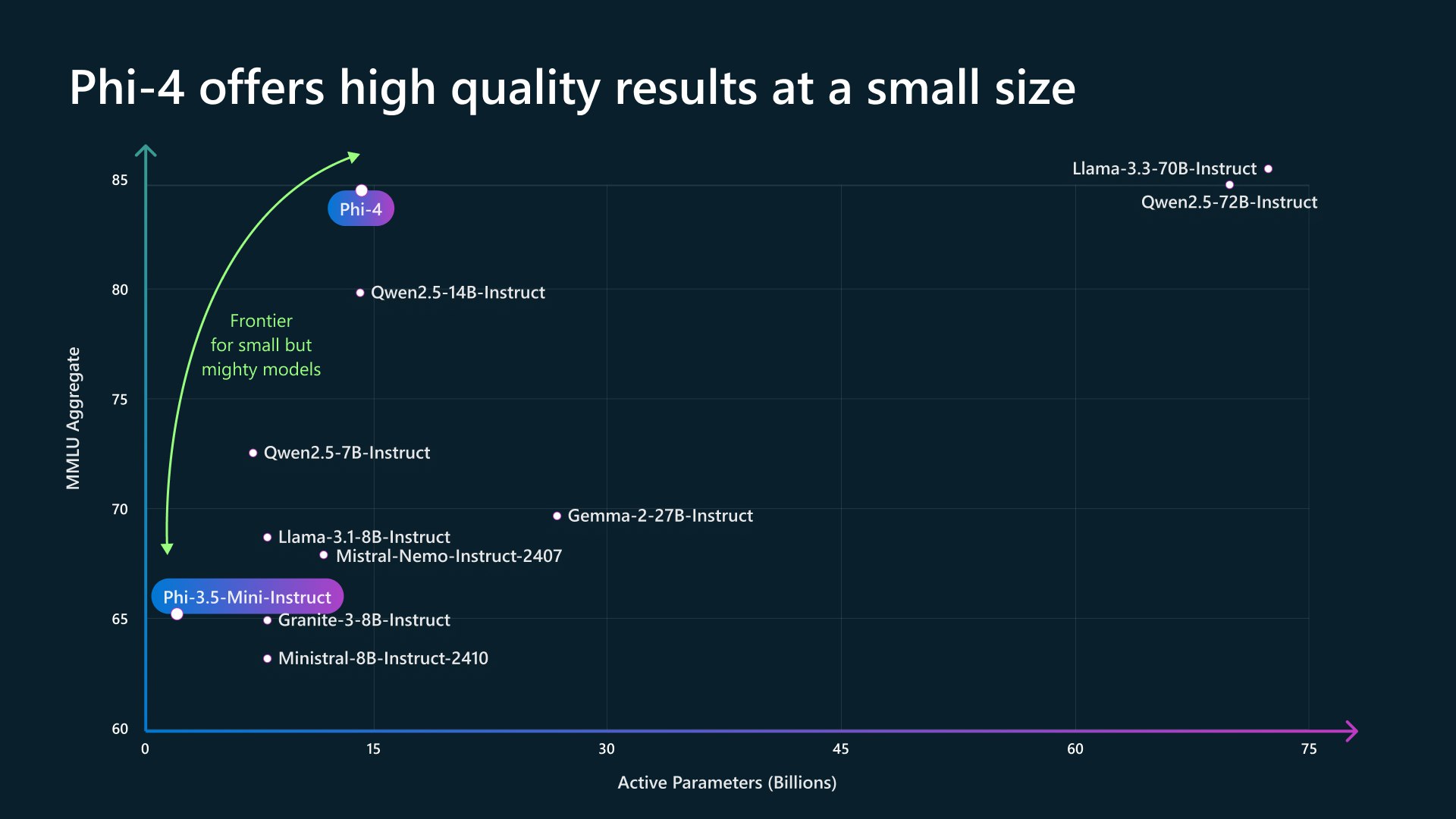
Phi-4, 14B参数的LLM
在MMLU上超过了Llama-3.3-70B-Instruct、Qwen2.5-72B-Instruct。相当厉害!
PHI历代模型
| 模型名称 | 年代 | 参数数量 | 架构 | 数据集描述 | 训练细节 | 上下文长度 | 精度 | 论文/报告链接 |
|---|---|---|---|---|---|---|---|---|
| Phi-1 | 2023 | 1.3B | Dense | 54B tokens (7B unique tokens) | 6 days, 8 A100 GPUs | - | fp16 | Textbooks Are All You Need |
| Phi-1.5 | 2023 | 1.3B | Dense | 30B tokens dataset, trained on 150B tokens | 8 days, 32 A100-40G GPUs | - | fp16 | Textbooks Are All You Need II: phi-1.5 technical report |
| Phi-2 | 2023 | 2.7B | Dense | 250B tokens dataset | 14 days, 96 A100-80G GPUs | 2048 tokens | - | Phi-2: The surprising power of small language models |
| Phi-3-mini-128k-Instruct | 2024 | 3.8B | Dense 32K vocabulary | 4.9T tokens | 10 days, 512 H100-80G GPUs | 128K tokens (4K variant also available) | - | Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone |
| Phi-3-small-128k-instruct | 2024 | 7B | Dense 100K vocabulary | 4.8T tokens | 18 days, 1024 H100-80G GPUs | 128K tokens (8K variant also available) | - | - |
| Phi-3-medium-128k-instruct | 2024 | 14B | Dense 32K vocabulary | 4.8T tokens | 42 days, 512 H100-80G GPUs | 128K tokens (4K variant also available) | - | - |
| Phi-3-vision-128k-instruct | 2024 | 4.2B | MLLM Base Phi-3 Mini | 500B visual and text tokens | 1.5 days, 512 H100-80G GPUs | 128K tokens | - | - |
| Phi-3.5-mini-instruct | 2024 | 3.8B | Dense | 3.4T tokens | 10 days, 512 H100-80G GPUs | 128K tokens | - | - |
| Phi-3.5-MoE-instruct | 2024 | 16x3.8B (6.6B active) | MoE model with 16 experts | 4.9T tokens | 23 days, 512 H100-80G GPUs | 128K tokens | - | - |
| Phi-3.5-vision-instruct | 2024 | 4.2B | MLLM Base Phi-3 Mini | 500B tokens (visual + text) | 6 days, 256 A100-80G GPUs | 128K Tokens | - | - |
| Phi-4 | 2024 | 14B | Dense | Synthetic data | 10 days, 512 H100-80G GPUs | 4096 tokens (extended to 16K) | - | Phi-4 Technical Report |
Question List
- Q1: 有LLM,还需要SLM吗?
- Q2:Phi4的效果如何?
- Q3:Phi4的主要改进是什么?
- Q4:Data
- Q5:Pretraining
- Q6:Post-Training
- Q7:Benchmarking
- Q8:Weaknesses
Q1: 有LLM,还需要SLM吗?
SLM = Small Language Models
优势1:见效快
小模型的训练好处是显而易见的,10天就是1个版本!
并且迁移到一个领域,只需要十天甚至更少,对生产力的提升一定是颠覆性的。
优势2:即使AGI来了,也不慌
结合之前Andrej Karpathy大神的观点:一个具备认知核心的模型可能只需要10亿参数就足够了。现有的模型大部分都浪费了很多容量来记住不必要的内容。如果只是需要一个认知核心模型的话,只需要蒸馏出10亿的参数就够了,这个模型不需要所有的知识内容,只要在必要时调用其他模型或者工具就可以。
优势3:有适用场景
- 我想需要一位前台或实习生,没必要招一位博士;平衡成本与产出
- 适配边缘算力(PC,手机等),即使端侧算力再提升,也不可能支持175的GPT3或1800B的GPT4;所以2B,8B,14B等SLM有广阔的发展空间。
所以,搞SLMs(Small Language Models),大有可为!
Q2:Phi4的效果如何?
优点:
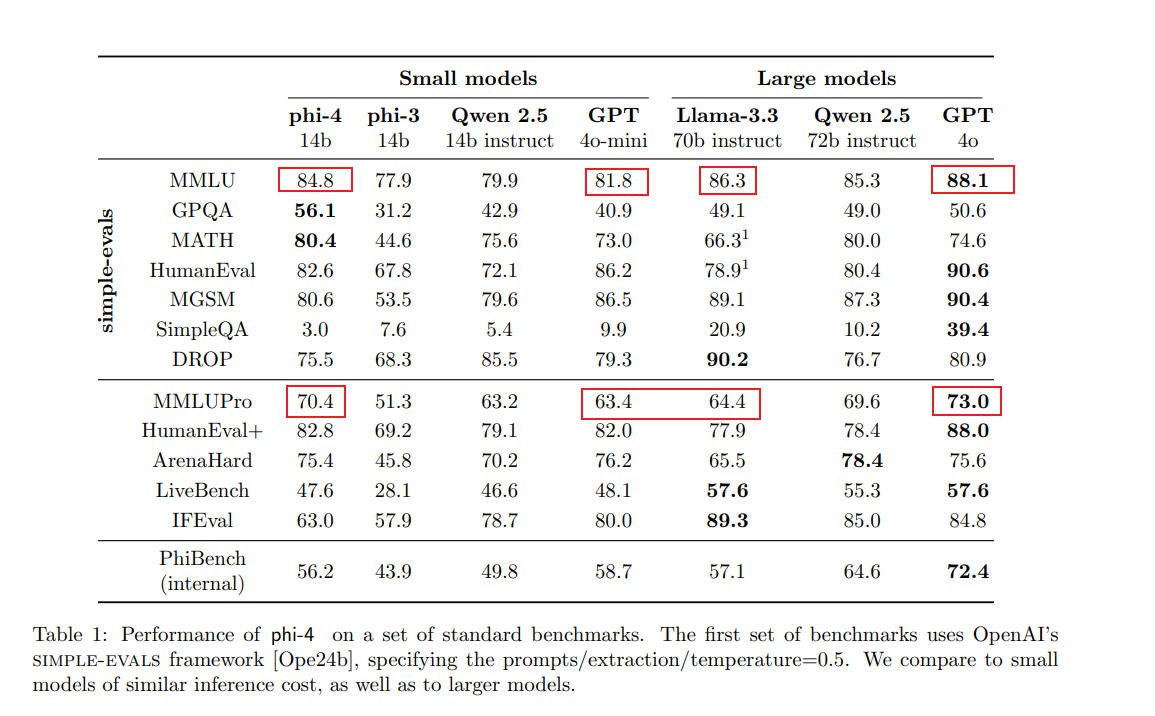
多语言理解能力-MMLU:phi-4 14b得分为84.8,已经超过了GPT-4o mini, 稍弱于Llam3.3, 但已经非常强了。
数学推理:phi-4 14b得分为80.4,非常出色,甚至超过了GPT-4o
编程能力:在HumanEval和HumanEval+测试中,phi-4 14b超过Llama3.3-72B和Qwen 2.5-72B。
缺点:
- 简单问答能力有限:GPQA优势明显,但SimpleQA较差;说明问题推理能力很强,但模型规模决定了常识性知识有限,导致SimpleQA较差。
- 指令遵循能力较弱: IFEval仅63,远弱于Llama-3.3的89.3。作者认为,原因在于合成数据未考虑这方面,但其能力是足够的,如果针对性合成数据,指标会有明显提升。
Q3:Phi4的主要改进是什么?
三大创新点
- 高质量的合成数据 高质量的合成数据(Pre-train & Mid-train),优先考虑reasoning和problem solving。
- 高质量的数据过滤 精心筛选书籍、代码库、web等高质量数据,提取能够帮助模型进行深度推理和调教模型的数据。
- Post-Training 精炼新的SFT数据集,结合DPO和Pivotal Token Search
应对过拟合&数据污染
- Decontamination:改进了数据过滤,避免Benchmark数据污染,从而导致在Benchmark上过拟合
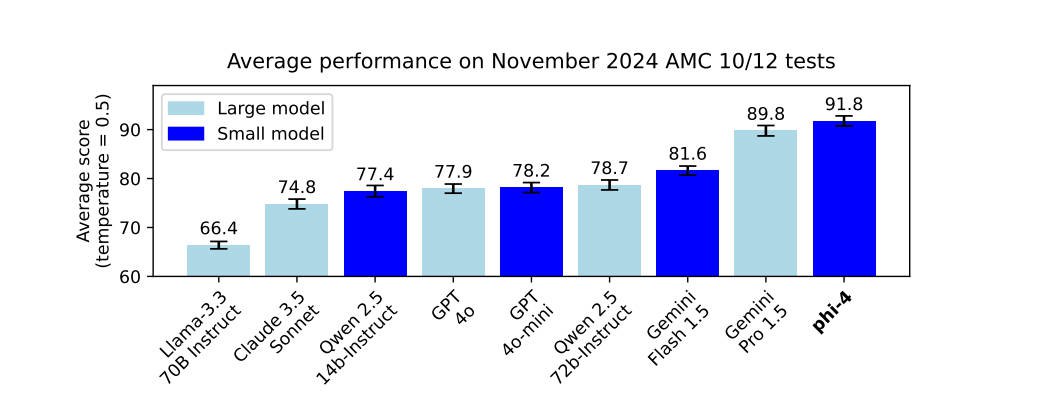
- AMC Benchmark:为避免过拟合,最可靠的方法是在新数据上测试,采用了202411的数据,
- 重点关注哪些原始问题不会出现在web上的benchmark,例如:GPQA。所以,在这方面效果才会这么好?
- Long Chain-of-Thought Models:开源模型中,只有QwQ-32B是基于O1模式的,达到了124.5分;但QwQ的参数量是Phi-4的2倍多,推理token量是4X多。
Q4:Data
Phi-4预训练阶段高度依赖高质量的合成数据以及高质量的有机数据源(有机表示来源于人工自然文本,非合成), 高质量数据源也作为合成数据的种子。
合成数据的目的
从2024下半年开始,各路大佬们包括openai、claude等基本都在合成数据上发力。
结构化与渐进式学习
有机数据集中,token之间的关系往往复杂且间接,具有跳跃性。模型在预测下一个token时,可能需要经过多个推理步骤才能建立联系,从而增加了学习难度。而合成数据中,每个token都是基于前一个token生成的,模型能够更轻松地掌握其推理模式。通过这种方式,合成数据能够以一种循序渐进的形式,将挑战以更易于学习的方式呈现。
例如,人类撰写的数学问题解决方案可能直接展示最终答案,但对于人类和LLM来说,这种直接输出难以实现。人类是通过非线性编辑得出答案,而模型预训练则要求线性生成。合成的数学问题解决方案则避免了这种障碍,使模型能够更有效地学习。
对齐推理场景
合成数据通常更接近模型实际需要生成的输出格式。
在这种数据上的训练,可以使模型的预训练体验与推理时遇到的场景更好地对齐。
这种对齐性确保模型在推理过程中所见的上下文与预训练数据一致。
例如,网络论坛的内容风格与LLM交互的语言风格差异较大。如果某个事实仅出现在网络论坛中,预训练模型可能认为该事实在其生成的对话中出现的概率很低。将这些事实转化为LLM常用的语言风格,可以使模型更容易在推理时访问这些信息。
合成原则
多样性:数据应覆盖每个领域的子主题与相关技能,这需要从多样化的有机数据源中筛选种子数据。
细致与复杂性:训练数据应包含反映领域复杂性和丰富性的示例,不仅限于基础内容,还包括边界案例与高级问题。
准确性:生成的数据需确保代码能够正确执行,证明过程有效,解释符合已知知识体系。
推理链:数据应鼓励系统性推理,通过分步教学的方式帮助模型掌握解决复杂问题的方法,从而生成连贯的输出。
Pretraining & Midtraining中的合成数据
Phi-4创建了50种类型的合成数据集,每种数据集依赖于不同的一组种子和不同的多阶段提示过程,涵盖多个主题、技能及交互形式,总计生成了约400B未加权tokens。
种子整理
合成数据集的生成始于从多个领域获得的高质量种子,使得可以创建与模型训练目标相匹配的任务。
- 基于Web和Code数据源 摘录和片段从网络页面、书籍和代码库中提取,重点关注那些展示高复杂性、推理深度和教育价值的内容。为了确保质量,我们采用两阶段筛选过程:首先,识别具有强大教育潜力的页面;其次,将选择的页面分段,并对每段的事实和推理内容进行评分。
- 问题数据集 从网站、论坛和 Q & A 平台收集了大量问题。采用多元投票技术对过滤以平衡难度。
具体而言,我们为每个问题生成了多个独立答案并应用多数投票来评估回答的一致性。
我们舍弃了所有答案一致(表明问题过于简单)或答案完全不一致(表明问题过于困难或含糊不清)的问题。
这个过滤过程生成的问题集挑战模型的推理和解决问题的能力,同时保持可实现性。
多数投票的结果用于拒绝采样生成中的参考答案。 - 从多样化来源创建问答对 借助语言模型,从书籍、科学论文和代码等有机数据中提取问答对。此过程不仅提取显式问答对,还通过检测推理链和逻辑进展,将问题解决中的关键步骤转化为问答形式。实验表明,这种生成方式比直接使用原始内容更能提升模型在学术及内部基准上的表现。
重写与增强
通过多步骤提示工作流程,将种子转化为合成数据。这包括将给定段落中的大部分 有用内容重写为练习、讨论或结构化推理任务。
自我修订
强化反思逻辑,初始响应通过反馈回路进行迭代优化,模型在此过程中对自身输出进行批评并随后改进,指导原则集中在推理和事实准确性。
代码和其他任务的指令反转
通过将现有代码片段反向生成任务描述或提示,将代码数据转化为指令-代码对。生成数据对以指令在前、代码在后的格式呈现,并保留原始代码与再生成代码高度一致的部分,以确保指令与输出的对齐性。此方法可推广至其他应用场景。(小说场景大有可为!)
代码及其他科学数据的验证
对于推理密集型合成数据集,团队引入验证机制。代码数据通过执行循环与测试进行验证,科学数据则通过提取科学材料中的问题,确保其高相关性、基础性和难度平衡性。
有机数据:Web and Q&A
Q&A数据
通过审阅公共网站、使用现有数据集和引入外部数据集,收集了数千万个高质量的有机问题及其解决方案。研究发现,问答数据对提升模型的数学推理能力和学术表现有显著作用。消融实验表明,与合成问题相比,有机问题的效果更为显著。为扩大数据集规模,采用多种方法生成了合成版本的有机问题。尽管这些重写问题对模型能力有所提升,但增益效果相对有限。由于收集的问题中有相当一部分缺乏准确答案,团队用合成生成的答案进行替换,并通过多数投票机制提高答案的准确性。所有收集的问题和答案均经过严格的去污染(decontamination)流程,确保不与测试集重叠。
去污染是某些学术基准测试可靠性的关键。例如,一些测试基准的变体可以在公开平台(如Hugging Face)上找到,而MMLU等基准测试常由网络数据汇编而成。
Web数据
为phi-4筛选了多种高质量有机数据源,重点关注推理密集型和细致内容(如学术论文、教育论坛和编程教程)。这些数据既直接用于训练,也作为合成数据生成的种子。高质量、准确的自然数据对合成数据生成至关重要,因为细微错误可能导致派生数据的质量显著下降。为此,采取了以下技术与策略:
- 目标性获取:选取公开许可使用的推理密集型文档库(如arXiv、PubMed Central、GitHub)及授权书籍,以确保内容的全面性、时效性和清洁度高于一般外部语料库。
- 过滤网页数据集:从大规模网页数据集中筛选少量高质量文档,用于涵盖信息丰富的长尾部分(如论坛、博客、课程材料和特定领域的wiki)。筛选采用小型分类器,基于约百万个LLM标注的训练数据运行。为避免过于集中于STEM内容,开发了专用流程以提升艺术、历史等非STEM主题的内容比例,同时去除语法异常或格式错误的文本。
- 多语言数据:引入多语言数据集以支持德语、西班牙语、法语、葡萄牙语、意大利语、印地语和日语等语言的处理。通过fastText语言识别模型分类文档,并结合分类器筛选高质量内容,确保数据的准确性与多样性。(不支持中文,反倒是一个很大的问题!)
- 自定义提取与清理:开发专用解析工具和清理流程,确保异构数据源之间的清洁度和一致性。针对HTML、TeX/MathML公式、代码块等脆弱内容,设计了精准提取工具,避免普通解析器可能引入的错误,同时去除广告等冗余内容并标准化格式。
Post-Training datasets
Phi-4的后期训练数据集包括以下两部分:
- SFT数据集:通过筛选优质的用户提示词,结合公开数据集与合成数据生成多种模型响应,并利用基于LLM的评估流程选出最佳响应。(这方面,open-ai积累了相当大的优势!)
- DPO:通过拒绝采样和LLM评估生成DPO数据对,部分数据对采用基于关键token的生成方法。
Q5:Pretraining
Model Architecture:Dense Decoder-only
Model Size:14B
Pretraining Context Length:4K
Mid-training Context Length:16K
Tokenizer:tiktoken tokenizer
Vocabulary Size:100,352
Attention Mechanism:全注意力机制
Pre-training Tokens:约10T个tokens
Learning Rate Schedule:线性预热与衰减学习率调度
Peak Learning Rate:0.0003
Weight Decay:0.1
Global Batch Size:5760
Training Hyperparameters:通过短期训练结果插值调整,并进行压力测试确保稳定性。预训练后进行中期训练,扩展上下文长度至16K。
Data Composition in Pretraining
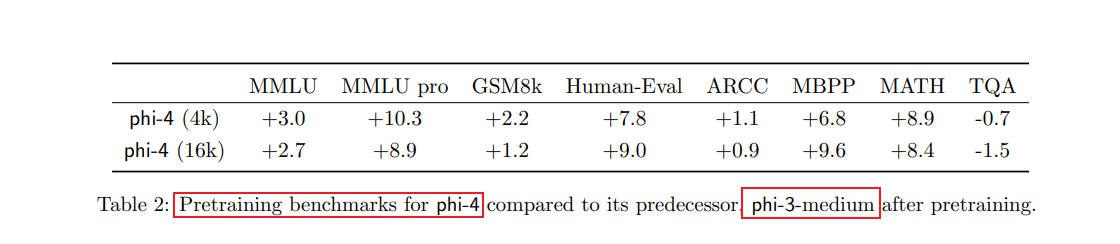
phi-3模型系列采用了两阶段的训练策略。
在第一阶段,使用主要由过滤后的网页数据组成的大部分训练tokens。
第二阶段的训练数据混合以合成tokens为主,辅以少量经过严格过滤的推理密集型网页数据。
随着合成数据的规模和复杂性增加,phi-3系列模型对非合成tokens的依赖逐渐减少。
以下为两项关键观察结果:
网页数据对推理密集型基准测试的作用有限:在合成数据上增加更多训练周期,比加入更多新的网页tokens带来的性能提升更显著。
仅使用合成数据训练的模型在知识密集型基准测试中的表现较弱,并且生成幻觉信息的几率增加(即输出错误或虚假的信息)
Data Mixture
为了在训练token预算范围内设计合理的预训练数据混合方案,团队尝试了多种不同来源tokens的分配方式,包括: 1)合成数据,
2)网页重写(作为合成数据的一个重要类别,主要包含对网页内容的直接重写),
3)过滤后的网页数据(分为推理密集型和知识密集型),
4)定向采集和有机数据(如学术数据、书籍和论坛),
5)代码数据。
采用1万亿tokens的训练预算进行了消融实验,以探索数据混合的最优配置。
并且观察到7B和14B模型性能结果高度相关。基于此,可以在7B模型上进行实验,并将发现直接应用于phi-4。
基于下表消融实验发现:
- 平均分配效果最差
- 合成数据效果最好,对推理能力提升很大,但对知识密集型效果较差。
- 最终结果是平衡了综合表现配比。
- 如果采用全合成数据,MMLU:84.8+3.3=88.1,已经达到了GPT-4o的水平!
- 但是,实验发现,随着模型进入后期训练阶段,性能差距逐渐缩小。未来,可以探索在端到端的数据混合方案。
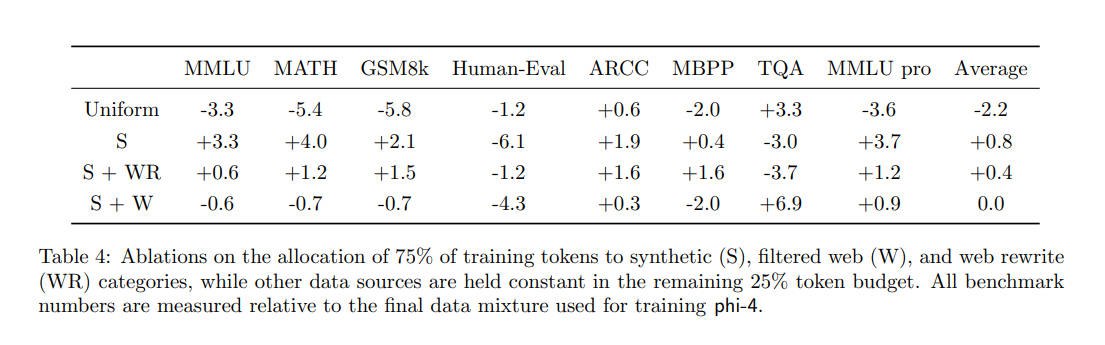
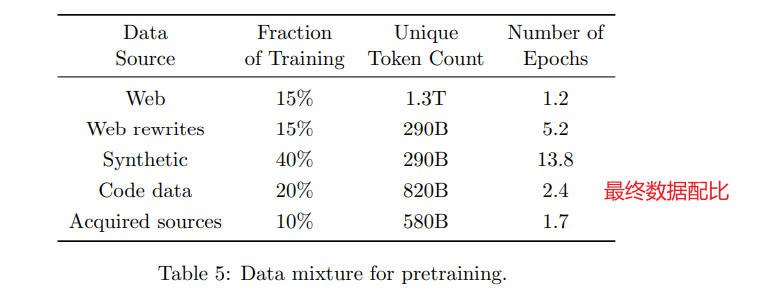
最终数据配比:
- 30%的网页和网页重写数据(各占一半)
- 40%的合成数据
- 20%分配给代码数据(包括合成代码和原始代码混合)
- 10%分配给定向采集数据源(如学术数据和书籍)
Mid-training
phi-4模型的中期训练阶段将上下文长度从4K扩展至16K。
为研究数据对长上下文性能的影响,进行了多项消融实验。结果显示,天然长上下文数据在相关任务中效果更佳。
Data: 增加更多8K以上的样本,并对16K以上样本加权
RoPE: 基本频率增加至250K
Learning Rate: 较预训练降低10倍
Total Token:250B
为了评估模型的长上下文能力,团队设计了一个包含实际场景的综合评估框架。
Recall(回忆任务):从随机生成的长JSON文件中,根据指定的键检索对应值(指标:SubEM,衡量子任务的精确匹配程度)。
RAG(检索后生成任务):从检索到的并被随机打乱的维基百科文档中回答问题,数据集包括NaturalQuestions、HotpotQA和PopQA,结果为所有数据集的平均值(指标:SubEM)。
Re-rank(重新排序任务):根据查询,对检索到的文档重新排序,挑选出前10个文档。此任务基于MSMARCO数据集(指标:nDCG@10,衡量前10个结果的排名质量)。
ICL(上下文内学习任务):利用多个少样本提示词进行上下文内学习,数据集包括TREC coarse、TREC fine、Banking77、NLU和CLINC150,结果为所有数据集的平均值(指标:F1,衡量分类性能)。
QA(问答任务):根据长文档回答问题,任务使用NarrativeQAv2数据集(指标:GPT-4o评分)。
Summ(摘要任务):对长篇法律文档生成摘要,任务基于MultiLexSum数据集(指标:GPT-4o评分) 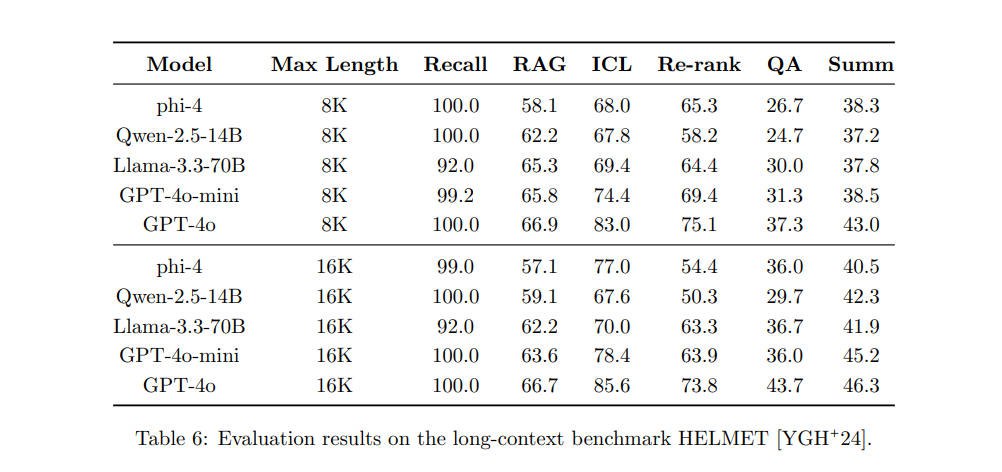
Q6:Post-Training
后期训练旨在将预训练的语言模型转变为用户可以安全互动的人工智能助手。
团队首先通过一轮SFT,接着应用基于关键token搜索方法的DPO训练,最后进行一轮基于完整长度偏好对的DPO训练。
模型使用标准的chatml格式进行微调,下面是两轮对话的示例模板: 
SFT
在此阶段,团队以 10−610^{-6}10^{-6} 的学习率对预训练模型进行微调,使用的数据来源于多个领域的高质量内容,包括数学、编程、推理、对话、模型身份和安全性等。
此外,他们还加入了40种语言的多语言数据。(大概率支持中文!!)
总计约8B tokens,所有数据均采用chatml格式。
DPO
团队使用DPO对模型进行人类偏好对齐,同时帮助模型避免不良行为。
DPO的数据涵盖了聊天格式、推理和负责任AI(RAI)等内容,并提高了模型在数学、编程、推理、鲁棒性和安全性等方面的能力。
他们在SFT模型上进行了两轮DPO训练。
为了生成第一轮DPO所需的数据对,团队引入了“关键token搜索”(PTS)技术。
在第二轮,即“判断引导的DPO”中,团队收集了大约85万对期望与不期望的输出。这些提示词来自公开的指令微调数据集,也包含了与安全性和负责任AI(RAI)相关的提示词。接下来,团队为每个提示词生成来自GPT-4o、GPT-4t和本模型的响应,并根据准确性、风格和细节为每对响应打分。得分较高的响应被标记为正向响应
两个阶段还包括了一些安全性和缓解幻觉的数据。
Pivotal Token Search, PTS
考虑一个生成模型,在给定提示词的情况下逐个生成Token作为回答。
对于每个生成的Token,可以计算在生成该Token时,模型给出的回答正确的条件概率,以及生成该Token前后,正确概率的变化。
这些变化反映了特定Token在最终结果中的重要性。通常情况下,最终的正确性会受到少数关键Token的影响。
例如,如图3所示,当模型输出数学解答时,生成一个关键Token会将解答从可能失败转变为成功,而某些低概率的Token则可能导致解答失败。
团队将这种具有重大影响的Token称为“关键Token”。
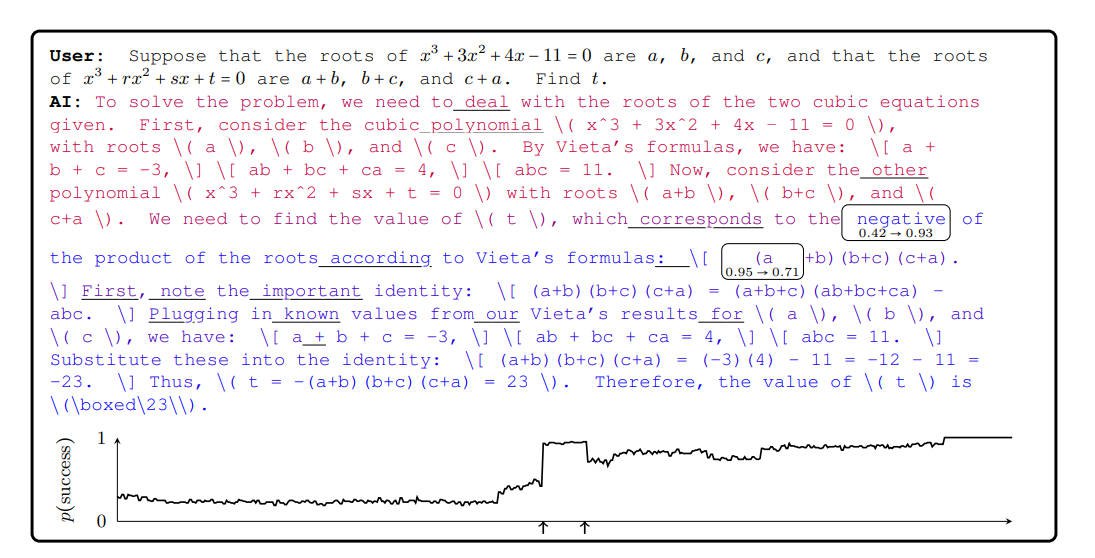
进一步来看,考虑将图3中的解答作为DPO中的完整接受响应。图中显示了许多Token的概率远低于0.31的负面概率,这些Token会增加噪音,稀释关键Token的梯度信号。更糟的是,某些低概率的Token会获得强烈的正向学习信号,从而影响模型的鲁棒性。
此外,当两段文本的差异较大时,单纯比较它们各自的下一个Token的对数概率并不太有意义。更合理的做法是,从文本开始偏离的第一个Token开始,信号应该来自于这里。
为了解决这一问题,团队提出了“关键Token搜索(PTS)”方法,用于生成专门针对关键Token的偏好数据,创建DPO配对,并使优化只作用于单个关键Token。
PTS方法通过识别某些用户查询 QQQ 的完整生成序列 Tfull=t1,t2,…T_{full} = t_1, t_2, …T_{full} = t_1, t_2, … 中的某个Token ti t_i t_i,这个Token对成功概率 p(success|t1,…,ti)p(success | t_1, …, t_i)p(success | t_1, …, t_i) 有显著影响,从而确定关键Token。PTS通过从 Q+t1,…,tiQ + t_1, …, t_iQ + t_1, …, t_i 开始进行补全采样,计算这些Token对成功概率的影响,并通过一个“oracle”进行验证。该算法通过递归分割Token序列来识别关键Token,并使用二分搜索来寻找这些关键Token。
为了提高样本效率,PTS只筛选出成功概率在0.2到0.8之间的问题,因为对于非常简单或困难的任务,关键Token的出现频率较低。
在数学问题的例子中,关键Token通常并非是错误,而是选择了一个不太有利的路径。通过生成针对这种选择的DPO数据,团队认为PTS能够使phi-4在其强项模式下表现得更好。
Hallucination mitigation
团队通过生成 SFT 数据和 DPO 配对来抑制模型的幻觉。如果模型无法回答问题,他们宁愿让其拒绝回答,也不希望它编造错误答案。这一措施大大减少了 SimpleQA 中的幻觉问题.
一个衡量标准是,在 SimpleQA 中,模型很少正确回答的问题在后训练过程中逐渐不再尝试。尽管 SimpleQA 的评估结果(F1 分数)显示基础模型得分更高,但团队认为最终模型的行为表现更好。 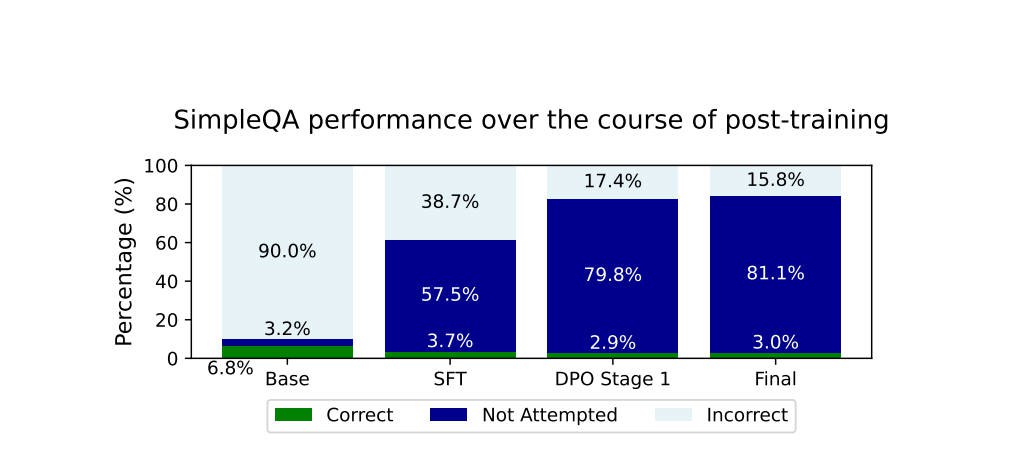
Post-Training Ablation
通常来说,关键token DPO在推理密集型任务(如 GPQA 和 MATH)中最为有效,而评审引导 DPO 对于需要 GPT-4评审的任务(如 ArenaHard)尤其重要。他们还发现,这两种方法在实际应用中是互补的,能够共同提升模型表现。
Q7:Benchmarking
Benchmarking Considerations
学术基准虽然广泛用于衡量LLM的进展,但它们存在一些局限,可能无法完全揭示模型的真实能力与不足。
这些局限包括:
- 数据污染:许多基准依赖于与预训练语料库重叠的数据集,这可能导致数据污染风险。尽管团队采取了广泛措施进行去重和去污染,包括使用标准的n-gram去重与去污染方法,这些方法并非在所有情况下都有效,尤其是在面对“重述”等情况时,因此无法完全排除泛化能力的潜在不确定性。
- 技能范围有限:大多数基准测试模型的技能范围较为狭窄,比如要求解答特定类型的数学题,或在某个年级水平上实现简单的Python函数。这样的测试方式无法全面反映模型的广泛能力和潜在弱点。
- 生成任务中的偏差:一些基准采用LLM作为评判者来评估生成的结果,但这些评判有时会优先考虑样式、流畅性或表面特征,而忽视推理过程的准确性和有效性,从而可能产生偏差。
- 多项选择题的局限性:依赖多项选择问题的基准,往往测试模型的猜测能力,模型通过模式匹配就能作出选择,而不一定依赖于推理和概念的有效利用。
为了克服这些问题,团队建立了一个名为PhiBench的内部基准,专门用于评估他们认为对phi-4开发至关重要的多种技能和推理能力。
该基准的设计目标如下: - 原创性:基准中的所有问题均由团队编写,确保不包含任何已在预训练数据中的内容。他们设置这个内部基准的目的是为了揭示模型在不同领域的泛化能力。
- 技能多样性:这个基准覆盖了多个任务,评估模型在不同维度的表现。例如,在编程测试中,不仅限于函数实现,还包括调试、扩展代码、解释代码片段等任务;在数学测试中,任务不仅包括解方程,还涉及识别证明中的错误或生成相关题目。这样能确保基准涵盖更广泛的技能和推理过程。
- 严格的生成任务评分:对于需要评估模型生成内容的任务,团队通过详细的评判说明(或“评分指南”)解决了LLM评分中常见的偏差问题。评分标准明确规定如何评估结果,强调准确性、逻辑结构和任务要求的遵循,同时减少对风格偏好的影响。他们观察到,这种做法显著提高了评分的一致性,并减少了主观偏好的负面影响。
PhiBench在优化phi-4过程中发挥了关键作用。团队利用它来指导数据集组合和超参数选择,从而实施更高效的后训练技术。同时,PhiBench也用于进行高信号的研究,帮助识别模型的弱点,并为新数据源的输入提供反馈。
Performance on Key Benchmarks
首先,实验报告了来自OpenAI的simple-evals基准的结果,这是一个评估MMLU、GPQA diamond、MATH 、HumanEval、MGSM和SimpleQA F1分数的框架(包括提示词、温度设置和抽取)。
团队还考虑了MMLU-pro、HumanEval+、ArenaHard和IFEval,并使用了内部框架以及提示词和抽取。
最后,他们使用了PhiBench,这是团队内部设计的一组评估任务。
phi-4在12个基准测试中有9个超过了最接近的同类现有模型Qwen-2.5-14B-Instruct。
尽管phi-4在SimpleQA、DROP和IFEval基准中的表现低于Qwen-2.5-14B-Instruct,但团队认为phi-4在SimpleQA上的表现实际上更优。
事实上,Phi-4基础模型在SimpleQA的得分高于Qwen-2.5-14B-Instruct,而团队在后训练过程中故意调整了模型的行为,旨在提升用户体验,而非单纯追求更高的基准分数。 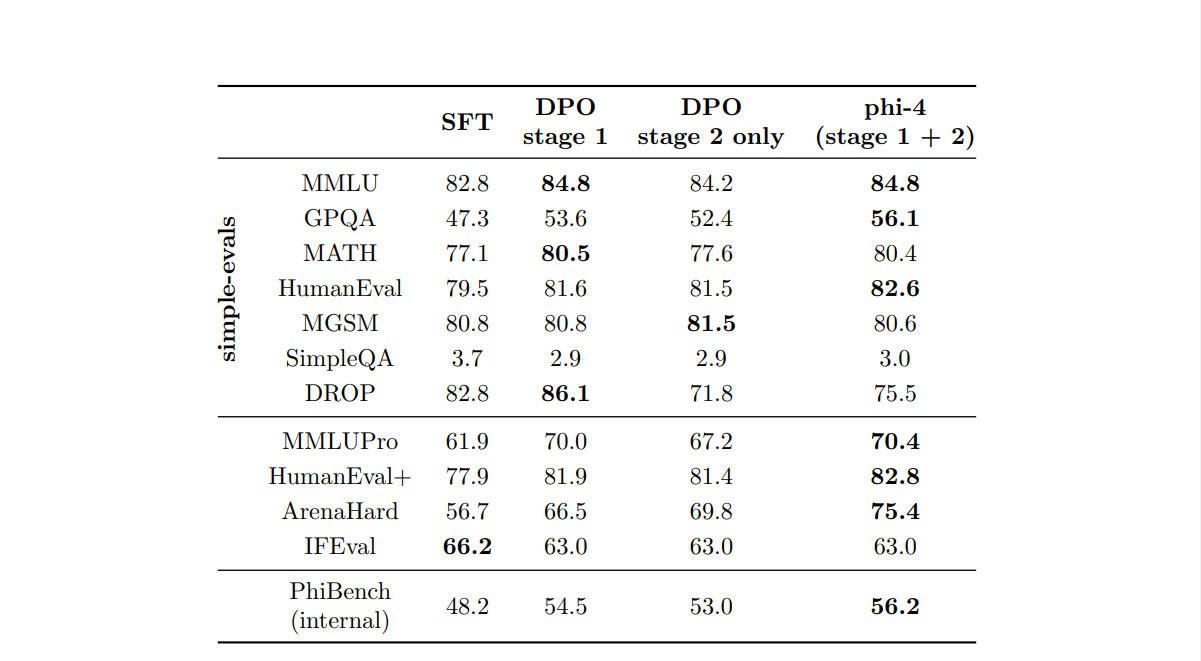
phi-4在STEM问答任务中表现非常出色。例如,在GPQA(研究生水平的STEM问题)和MATH(数学竞赛)任务中,phi-4的得分甚至超越了其参考模型GPT-4o。在编程方面,phi-4在HumanEval和HumanEval+测试中的表现超过了任何其他对比的开放权重模型,包括体量更大的Llama模型。
phi-4的表现最弱的基准测试是SimpleQA、DROP和IFEval。团队认为,simple-evals报告的前两个得分过于简化,未能准确反映模型在这些任务上的实际表现。然而,IFEval揭示了模型的一个真实弱点——它在严格遵循指令方面存在困难。尽管团队在合成数据生成时并未特别强调严格的指令遵循,但他们有信心通过有针对性的合成数据,phi-4在这一方面的表现可以显著改善。
Q8:Weaknesses
虽然phi-4在语言理解和推理能力上与更大规模的模型相当,但在某些任务中,尤其是在处理事实性错误(幻觉)时,它仍然受到规模限制。例如,当“X”是一个可能的人的名字时,模型有时会回应类似“X是谁?”的提示词,并生成一个虚构的人物传记。通过将模型与搜索引擎结合,这一问题有所改善,但无法完全消除事实性错误。
尽管phi-4在回答问题和进行推理任务时表现较强,但它在严格遵循详细指令方面的表现较弱,特别是对于涉及特定格式要求的任务。例如,当要求生成严格的表格格式、遵循预定义的项目符号结构,或精确匹配风格要求时,模型可能会产生偏离预设规范的输出。这一限制部分源于模型的训练重点,主要侧重于问答和推理任务的数据集,而非指令跟随任务。
即使在推理任务中,phi-4也有可能出错。例如,当被问到“9.9和9.11哪个更小?”时,模型可能错误地认为“9.9小于9.11”。
此外,由于数据中包含大量的思维链示例,phi-4有时会给出冗长的回答,即使是简单的问题,这可能使得用户交互变得冗长繁琐。团队还注意到,尽管phi-4能够作为聊天机器人使用,它已经经过优化,专注于提高单轮查询的性能。
尽管团队在RAI方面做了大量工作,但仍然面临一些挑战,如偏见的再现或放大、不当内容生成以及安全问题。通过精心挑选训练数据、进行针对性的后训练,以及从红队测试中获得的反馈,团队在多个方面缓解了这些问题,但尚未完全解决这些挑战。