Intro Text2Image models which use MLLM (PGv3)
So so excited to see the progress of Text2Image models which use MLLM. Expecting since 2023!!!
Intro
非常高兴看到类似这样文章,LLM + DiT.
2023年 ~ 2024年Q2,一直找类似的模型,因为LLM已经很成功了;但是SD、SDXL、SD3、SD3.5、Flux仍然抱着CLIP、T5不放。 这些文生图模型最难的问题不是生图不好看,而是生图和用户想要的不一致。
不知道为什么没有人做这样的尝试?成本太高?不好训? 很高兴目前看到了希望:
- 202409 Playground V3: Playground v3: Improving Text-to-Image Alignment with Deep-Fusion Large Language Models
- 202411 Qwen2VL-Flux: https://github.com/erwold/qwen2vl-flux/blob/main/technical-report.pdf
本来是想一篇写完呢,结果读完PGv3后,太过经验,它值得单出一篇!!!
要解决什么问题?
文生图模型从2022年开始已经非常成功了,从娱乐向逐渐转向了生产向。
但一直面临着两个重大挑战:
- 在整合参考图像时保持语义一致性和风格保真度
- 生成过程提供细粒度控制
主要原因:文本编码器的多模态理解能力有限,它们难以有效地弥合文本描述和视觉特征之间的语义差距
为了解决这个问题,有两个成熟的方向:
- 专注于提高文本编码器的能力,像Stable Diffusion和FLUX.1这样的模型结合了T5-XXL和CLIP以获得更好的文本理解
- 探索基于参考的生成,通过各种控制机制,如空间条件或注意力操作
目前仍然有很大提升空间。
Idea
充分利用LLM内部提示理解,实现更好的文本提示遵循、复杂推理和准确文本渲染等能力
TextEncoder
- 原有做法:采用T5-Encoder或Clip的最后一层输出。
- 优化思路:Transformer中每一层都捕获了不同的表示(单词级或句子级),LLM中信息的连续性是生成能力的关键,需要保留其流动性。
- 创新做法:设计t2i模型,复制LLM所有Transformer块,接受LLM每个对应层的隐藏嵌入输出作为条件输入,充分利用LLM的完整思考过程,引导t2i模型模仿LLM的推理和生成过程。
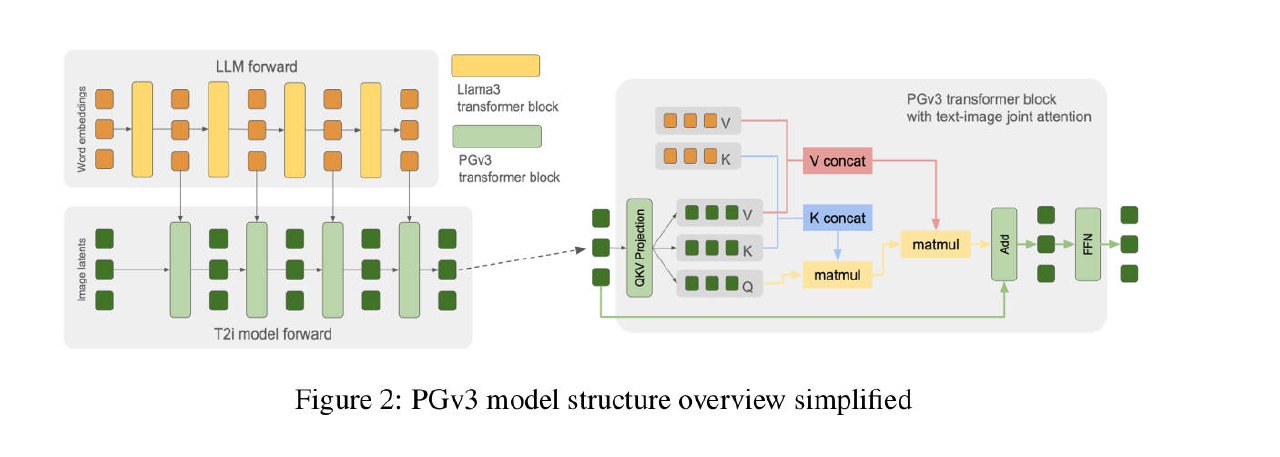
Model Architecture
LLM(Llama 3 8B) + DiT(24B)
- 与传统将图像和文本特征分别执行Self-Attention不同,这里执行了单一的联合注意力操作(拼接文本和图像特征)。类似MMDiT的理念,但这个设计更加简约,更彻底地利用了文本编码器
- 在扩散采样过程中,语言模型部分只需要运行一次,就可以生成所有中间隐藏嵌入。
- U-Net skip connections between transformer blocks [占坑]
- Token down-sampling at middle layers [占坑]
- Positional embedding - RoPE - expand-PE [占坑]
- New VAE - 16通道 [占坑]
- 【架构图缺少了U-Net、VAE的位置,待后续补充】 [占坑]
Training
- Noise schedule - EDM
- Multiple Aspect-Ratio Support
- Multi-Level Captions per Image - 非常棒的想法!
1
2
3
4
5
6
7
8
9
自研了Captioner, 对于每张图像,我们合成了六种不同长度的字幕,从细粒度细节到粗略概念。
在我们的工作中,我们通过生成多级字幕来进一步改善这些字幕条件,以减少数据集偏见并防止模型过拟合。
对于每张图像,我们合成了六种不同长度的字幕,从细粒度细节到粗略概念。
在训练过程中,我们在不同迭代中为每张图像随机采样这些六个字幕中的一个。
使用多级字幕的想法是帮助模型学习更好的语言概念层次结构。
这允许模型不仅要学习单词和图像之间的关系,还要通过以不同概念细节水平查看同一图像来理解单词之间的语义关系和层次结构。
结果,我们的模型在响应涉及一般概念的简短提示时表现出更大的多样性,并且在提供高度详细描述时更紧密地遵循提示。
此外,当在数据样本较少的数据集上训练时,例如在监督微调(SFT)阶段,多级字幕有助于防止过拟合并显著增强模型将 SFT 数据集的良好图像属性泛化到其他图像领域的能力。
Training stability
使用放弃问题梯度代替传统的梯度裁剪,对训练稳定性效果明显。因为,梯度裁剪只减少了梯度的大小,但不会改变权重更新的方向;因此,权重仍然可能向崩溃移动。
Captioning Model
- 采用了标准的VLM架构:Vision Encoder、Adapter、LLM。高分辨率VE非常重要。
- Caption评估-CapsBench
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
主要有两种评估指标:
1. 基于参考的指标
- BLEU、CIDEr、METEOR、SPICE
- 这些度量标准使用一个真实描述或一组描述来计算相似度,作为质量度量
- 缺点:分数受到参考格式的限制
2. 无参考的指标:
- CLIPScore、InfoMetIC、TIGEr
- 这些方法使用来自参考图像或图像多个区域的语义向量来计算所提出Caption的相似性指标。
- 缺点:对于密集图像和长而详细的字幕,语义向量将不具备代表性,因为它们将包含太多的概念。
提出了一个新颖的评估方法:** 基于问题的指标 ** 。
从Caption中生成问题,并使用这些问题评估所提出的Caption,有助于全面评估文本到图像模型的效果。
受到DSG和DPG-bench的启发,研究人员提出了一种反向的图像描述评估方法:
在17个图像类别中生成「是-否」问答对:通用、图像类型、文本、颜色、位置、关系、相对位置、实体、实体大小、实体形状、计数、情感、模糊、图像伪影、专有名词(世界知识)、调色板和色彩分级。
在评估过程中,使用语言模型仅基于候选描述回答问题,答案选项为「是」、「否」和「不适用」。
CapsBench包含200张图像和2471个问题,平均每张图像12个问题,覆盖电影场景、卡通场景、电影海报、邀请函、广告、休闲摄影、街头摄影、风景摄影和室内摄影。
效果定性评估
- 摄影作品
Ideogram-2: 遵循提示能力较差,皮肤纹理逼真
Flux-Pro: 皮肤纹理过于光滑,类似油腻或3D渲染的效果;但提示语遵循最好。美学相对较好。
PGv3: 在遵循提示和生成逼真图像方面都表现出色,中庸之作 - Prompt-Following
对提示语的遵循很好,甚至超越了Flux-Pro, 特别是对于较长的Prompt 得益于其强大的提示跟随和文本渲染能力,PGv3 能够复制带有定制文本的趋势表情包,并创造出具有无限角色和构图的全新表情包。
- RGBColorControl:不敢相信!!!
PGv3 在生成内容中实现了异常精细的颜色控制,超越了标准调色板。 凭借其强大的提示跟随能力和专业训练,PGv3 使得用户能够使用精确的 RGB 值精确控制图像中每个对象或区域的颜色,这非常适合需要精确颜色匹配的专业设计场景。 PGv3 接受整体调色板,自动将指定的颜色应用到适当的对象和区域,并且可以根据用户定义为特定对象提供专用的颜色值。
- Multilingual Prompt Input
English, Spanish, Filipino, French, Portuguese, and Russian 接受多语种输出,并且能保持很好的一致性! 输出只能是英语,素材限制
效果定量评估
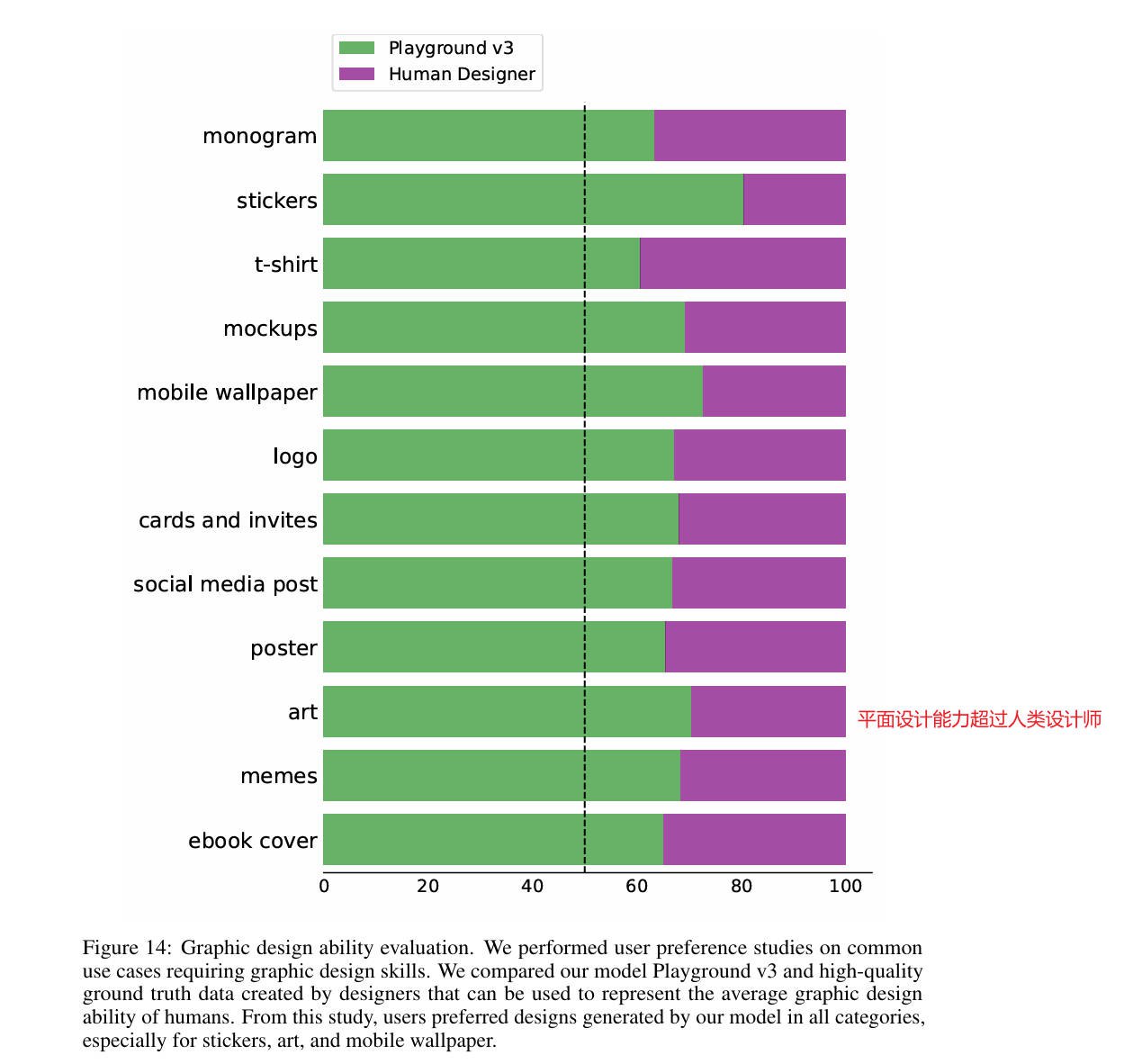
- 平面设计能力:超越人类设计师
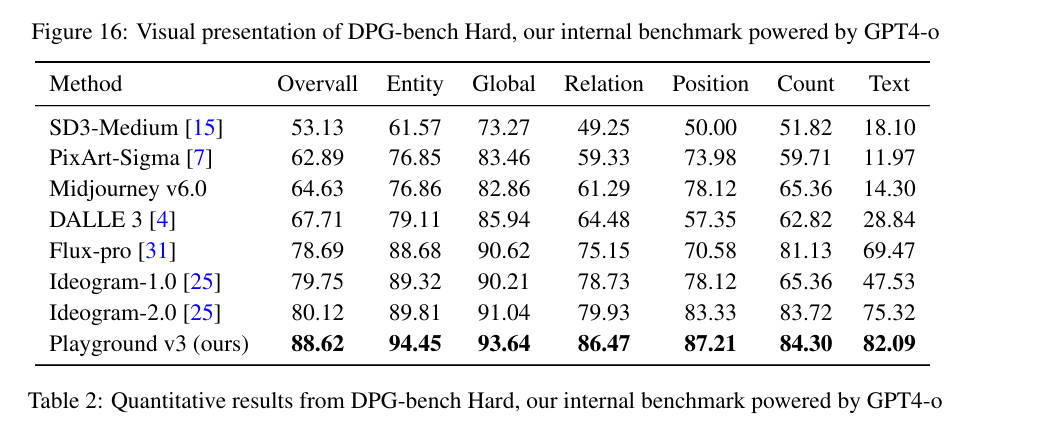
- 图文对齐评估:
- DPG-bench: 高于DALLE3和SD3-Medium

- DPG-bench hard: 超过Flux-Pro
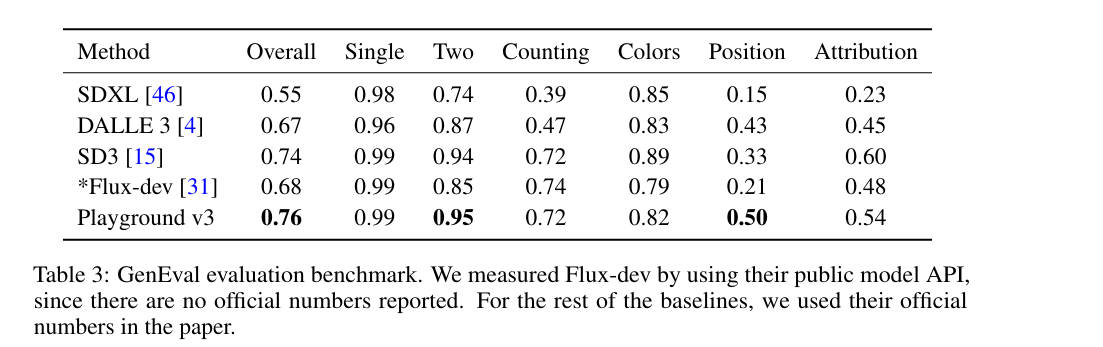
- 图像-文本推理评估:
- GenEval: 超过SD3
- 文字合成评估
- Mario-eval-1k: 高于Flux-pro

- 图像质量评估
- ImageNet
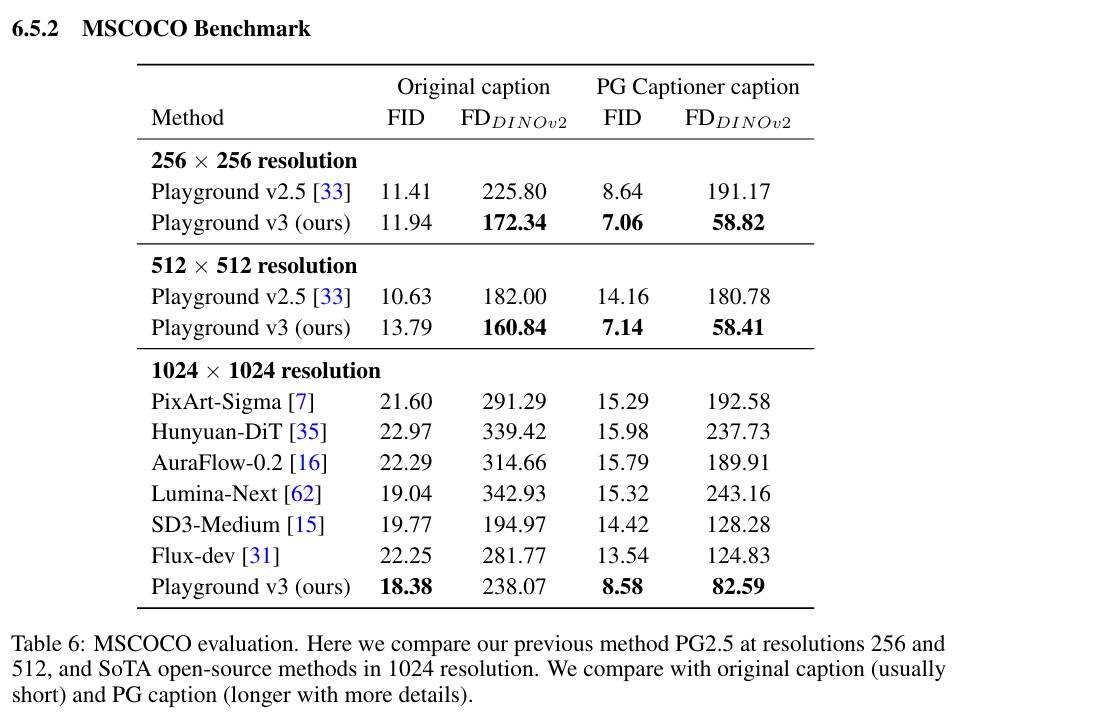
- MSCOCO: 优于Flux-dev
- VAE重建评估

结论
Playground v3,这是一个具有强大提示遵循能力、推理和文本渲染能力的最先进的文本到图像生成模型。效果超过我之前的想象,特别是支持调色板!